

Before we jump into headings, let’s set the stage. It’s 2025, analysts are expected to be “crypto-fluent” by default, and on‑chain metrics уже не экзотика, а обычный столбец в дашборде рядом с CRM и продуктовой аналитикой. Проблема в том, что у большинства команд путь от блокчейна до таблицы в BI‑инструменте усеян костылями: скрипты на коленке, непонятные лаги, рассыпающийся пайплайн. Ниже — практическое руководство: как построить on‑chain data ingestion так, чтобы аналитика была устойчивой, проверяемой и понятной команде, а не только одному «локальному блокчейн‑гуру».
—
What “on-chain data ingestion” actually means
On‑chain data ingestion — это систематическое получение, нормализация и загрузка данных из блокчейнов (транзакции, логи, состояния контрактов) в вашу аналитическую среду: хранилище, lakehouse или специализированную платформу. В отличие от разовых выгрузок через скрипт, ingestion — это повторяемый и управляемый процесс, который работает 24/7, документирован и мониторится, как любой серьёзный data pipeline. Важно разделять сами данные (сырые блоки и события) и слой логики (как вы интерпретируете конкретный смарт‑контракт или протокол).
Если говорить формально, в контексте блокчейна нам пригодятся несколько базовых определений. Block data — это набор транзакций и служебной информации, включённой майнерами или валидаторами в блок. Transaction — отдельное действие пользователя или контракта (перевод токена, вызов функции, деплой контракта). Event / log — структурированное сообщение, которое смарт‑контракт записывает в лог при выполнении функции. Именно события чаще всего становятся основой аналитики, потому что они лучше структурированы и описывают бизнес‑события (swap, stake, mint), а не только низкоуровневые вызовы.
—
How on-chain analytics differs from “normal” analytics
На первый взгляд, работа с блокчейн‑данными похожа на обычную продуктовую аналитика: у вас есть события, пользователи (адреса), сущности вроде токенов и протоколов. Но существуют критические отличия, которые влияют на архитектуру ingestion‑пайплайна. Во‑первых, данные в блокчейне неизменяемы — вы не можете «исправить» некорректную транзакцию; максимум, можно добавить компенсирующее действие. Во‑вторых, нет централизованного API: у каждого L1 и L2 — свой нодовый стек, форматы логов и нюансы RPC. В‑третьих, сущности анонимны: один адрес может представлять биржу, бота, DAO или обычного пользователя, и это сильно усложняет сегментацию.
Сравним с классическим web‑событийным трекингом. Там вы контролируете схему событий, версионируете её и можете навесить строгую типизацию. В on‑chain мире каждое новое децентрализованное приложение приносит собственный набор контрактов и событий; backward‑compatibility далеко не всегда соблюдается. Вот почему многие команды полагаются на on-chain data analytics tools и специализированное blockchain analytics software for data teams: оно уже умеет распознавать популярные протоколы и нормализовать их схему. Ваша задача — понять, где вам достаточно типовых инструментов, а где критично строить свою логику поверх сырых данных.
—
High-level architecture of an on-chain data ingestion platform
Если оставить детали в стороне, любую on‑chain data ingestion platform можно свести к нескольким логическим слоям: источник, доставка, хранение, моделирование, доступ для аналитиков. Независимо от того, используете ли вы готовый сервис, on-chain data analytics tools или строите всё на своём дата‑лейке, паттерн остаётся похожим на классический ETL/ELT, просто источник данных — блокчейн и его экосистема нод.
Представим архитектуру в виде текстовой диаграммы.
[Diagram: “On‑chain source” → “Access layer (nodes / APIs)” → “Ingestion jobs (stream / batch)” → “Raw storage (data lake / warehouse)” → “Modeling (dbt / SQL / custom jobs)” → “Analytics & BI (dashboards, notebooks, ML)”]. На входе у вас несколько блокчейнов или rollup‑сетей, далее слой доступа (собственные ноды или провайдер), затем процесс, который вытягивает новые блоки и события и складывает их в сырую зону. Через поверхностный слой трансформаций вы получаете уже «человеческие» таблицы: swaps, trades, loans, NFT transfers.
—
Step 1. Define use cases before choosing any tool
Самая частая ошибка — начать с выбора “best blockchain data provider for analysts”, не сформулировав, какие бизнес‑вопросы вы хотите закрыть. Прежде чем подписываться на дорогой real-time blockchain data API for analytics, имеет смысл выписать 5–10 ключевых сценариев: например, мониторинг активности кошельков институциональных клиентов, анализ ликвидности по DEX‑ам, отслеживание аномалий по крупным переводам. Это поможет решить, какие сети, какие типы данных и какую свежесть вам действительно нужно поддерживать.
Хороший рабочий подход — собрать кросс‑функциональную группу из продуктовых аналитиков, риск‑команды и людей из отдела стратегии. Вместе вы формируете список «обязательных» и «желательных» метрик. Обязательные метрики — это то, что влияет на ключевые KPI бизнеса: объём трейда клиентов, доля on‑chain активности по сравнению с off‑chain, концентрация ликвидности у топ‑адресов. Желательные метрики — более исследовательские: выявление кластеров ботов, поведение NFT‑коллекционеров, оценка эффективности новых токеномик‑механик.
—
Step 2. Choose your access layer: node vs provider
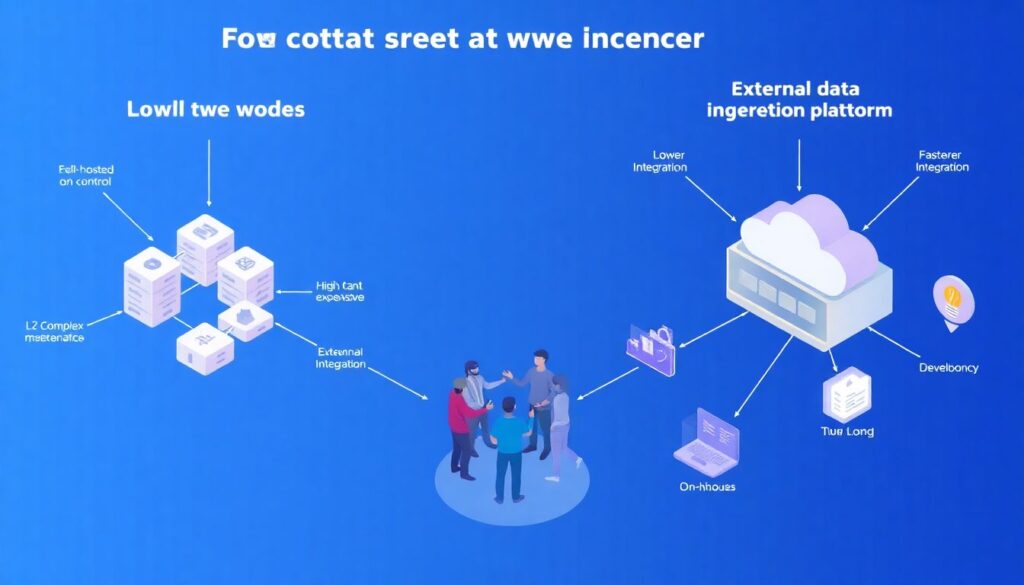
Теперь нужно решить, как вы будете извлекать данные: через свои ноды или через внешние сервисы. Первый вариант даёт максимальный контроль, но дорог и сложен в поддержке, особенно если вы работаете сразу с несколькими L1 и L2. Второй вариант — использовать внешний on-chain data ingestion platform или generic RPC‑провайдер — снимает часть проблем, но вы начинаете зависеть от чужой инфраструктуры, её SLA и политики по историческим данным. В 2025 году большинство аналитических команд комбинируют оба подхода: критические потоки идут через свои ноды, исследовательские — через внешние.
Если вам нужны лишь агрегированные метрики по популярным сетям, логично ориентироваться на on-chain data analytics tools, в которых уже есть предрасчитанные таблицы и схемы для основных протоколов. Если же вы хотите строить конкурентное преимущество на уникальной аналитике, рано или поздно придётся опуститься ближе к сырому слою. При выборе провайдера смотрите на три параметра: покрытие сетей и данных, производительность и лимиты, качество документации. Сравните, насколько просто воспроизвести один и тот же запрос через разных поставщиков, и оцените скрытые издержки — например, стоимость сверхлимитных запросов при пиках активности сети.
—
Step 3. Design the ingestion flow: streaming vs batch
Дальше вы решаете, как именно данные будут попадать к вам: потоком (streaming) или пакетами (batch). Для мониторинга аномалий, выявления фронт‑раннинга и поддержки real‑time‑дашбордов пригодится streaming с задержкой в секунды или десятки секунд. Для квартальной отчётности или исследовательских задач достаточно пайплайнов, которые раз в несколько минут или часов подтягивают новые блоки. На практике вы почти всегда комбинируете оба режима, при этом часть логики держите возле источника, а часть — уже в хранилище.
Текстовая диаграмма для гибридного варианта может выглядеть так.
[Diagram: “Chain → Stream job (Kafka / pub-sub)” → “Hot store (cache / OLAP)” для real‑time дашбордов; параллельно “Chain → Batch job (Airflow / cron)” → “Data lake (S3 / GCS)” → “Warehouse (BigQuery / Snowflake)” → “BI tool”]. Важно, что оба контура используют согласованную схему: вы не хотите, чтобы дневной отчёт и real‑time‑панель считали метрики по‑разному. Поэтому схемой лучше управлять централизованно, используя verison‑controlled модели и unit‑tests для ключевых трансформаций.
—
Step 4. Set up storage: raw, staging, mart layers
Даже если вы пользуетесь готовым blockchain analytics software for data teams, у вас всё равно будут свои слои данных внутри хранилища. Raw layer — это максимально близкая к источнику форма: блоки, транзакции, события с минимальными изменениями (добавили только технические поля вроде времени загрузки). Staging layer — промежуточные таблицы с развернутыми и нормализованными структурами (например, раскодированные topics и data событий, приведённые к удобным типам). Mart layer — бизнес‑ориентированные таблицы и витрины, на которых живут ваши дашборды и отчёты.
Практически это выглядит так. Вы создаёте один набор схем для сырых данных, которые грузятся в режиме «append‑only», без апдейтов. Затем поверх него — слой промежуточных моделей, где вы приводите адреса, токены и идентификаторы протоколов к единым справочникам. Наконец, на верхнем уровне появляются витрины вроде `fact_trades`, `fact_user_positions`, `dim_wallet_segments`. Такой трёхслойный подход облегчает отладку: если в отчёте обнаружились странные значения, можно спуститься на уровень ниже и понять, ошибка в моделях или проблема в исходных событиях.
—
Step 5. Normalize entities: addresses, tokens, protocols
Блокчейн не знает, что такое «пользователь», «клиент» или «маркетмейкер»; он оперирует только адресами и байтами. Поэтому один из важнейших шагов в on‑chain data ingestion — семантическая нормализация сущностей. Вам нужно связать адреса с контекстом: это биржа, мост, DeFi‑протокол, смарт‑контракт вашего продукта или кошелёк конкретного клиента. Без этого любые продвинутые on‑chain метрики превращаются в абстрактную статистику по бессмысленным строкам.
Типичный pipeline нормализации включает несколько источников.
– Открытые справочники: списки бирж и протоколов, метки от открытых проектов, данные из explorers.
– Внутренние данные: mapping ваших клиентов к их on‑chain адресам и контрактам.
– Эвристики и ML‑модели: кластеризация адресов, принадлежность к ботам, связи с известными сущностями.
Все эти источники собираются в единый reference‑layer, который затем подмешивается ко всем вашим mart‑таблицам. Чем аккуратнее вы строите этот слой, тем более осмысленными становятся отчёты: вы начинаете видеть не просто сумму переводов, а долю оборота, сделанную реальными пользователями, биржами или прокси‑контрактами.
—
Step 6. Add modeling and metrics layer
Как только сырые данные упорядочены, приходит время моделирования. Тут вы решаете, как именно будет считаться каждая метрика: что такое «активный пользователь», как вы определяете уникальный swap, в какие моменты фиксируете остатки в пулах ликвидности. Без чётко определённого metrics layer разные команды начнут считать базовые показатели по‑разному, и on‑chain аналитика превратится в бесконечные споры о цифрах вместо обсуждения выводов.
Обычно для моделирования используют SQL‑ориентированные инструменты (dbt или аналоги) поверх хранилища. Сам процесс напоминает классический аналитический ETL, но с несколькими особыми приёмами: вам приходится аккуратно разворачивать логические транзакции, которые могут включать десятки внутренних контрактных вызовов; строить временные снапшоты состояния контрактов; учитывать reorg‑и в сетях с вероятностью отката блоков. По возможности каждую бизнес‑метрику сопровождают чёткой текстовой спецификацией и тестами, которые проверяют базовые инварианты: например, суммарный баланс токена по всем адресам не должен расходиться с его totalSupply.
—
Step 7. Data quality, monitoring and backfilling
On‑chain пайплайны склонны ломаться в самые неудобные моменты: при обновлении протокола, форке сети, появлении нового типа события. Поэтому часть “start‑to‑finish guide” обязательно должна касаться качества данных и мониторинга. Минимальный набор — это алерты на задержку ingestion, на резкие отклонения по объёмам транзакций, на рост количества ошибок при парсинге событий. Более продвинутый вариант — тесты на уровне моделей: если количество активных кошельков внезапно падает до нуля, система должна подсветить это как возможный баг, а не реальность.
Отдельная тема — backfilling: перерасчёт истории, когда вы обновляете логику или добавляете новые сущности. В отличие от традиционных источников, блокчейн‑история огромна и постоянно растёт, поэтому «пересчитать всё с нуля» зачастую просто слишком дорого. Типичный подход — хранить в моделях версии логики и пересчитывать выборочные диапазоны блоков, которые критичны для отчётности. Также используют incremental‑модели, которые обновляются только для новых блоков и периодически проходят через полноформатный перерасчёт для sanity‑check.
—
Step 8. Governance, security and access control
Даже если вы работаете сугубо с публичными сетями, governance и безопасность в on‑chain ingestion‑проекте важны не меньше, чем в классических DWH‑сценариях. Во‑первых, аналитика нередко комбинирует публичные транзакции с приватными данными клиентов — и эти слои нужно строго разделять. Во‑вторых, многие юридические юрисдикции в 2025 году установили собственные правила по использованию и хранению данных блокчейна: от требований к анализу рисков AML до обязательного логгирования доступа к чувствительным витринам.
В практическом плане имеет смысл использовать ролевую модель доступа к данным: одни роли видят только агрегаты, другие — полный сырый слой, третьи — только обезличенные витрины. Управление схемой и бизнес‑логикой лучше вести через Git‑репозитории с code review, чтобы любые изменения моделей были прозрачны и проверяемы. Наконец, не забывайте про аудит внешних поставщиков: если ваш real-time blockchain data API for analytics принадлежит сторонней компании, нужно понимать, как они защищают свои ноды и журналы запросов.
—
Step 9. Tools landscape in 2025: build vs buy
К 2025 году рынок решений для on‑chain аналитики сильно взрослеет. Появилось множество on-chain data analytics tools, которые обещают «аналитику в один клик», а также серьёзные enterprise‑решения — от общих data‑платформ до нишевых сервисов для DeFi, NFT и GameFi. С другой стороны, крупные компании всё чаще создают собственные стеки поверх облачных lakehouse‑технологий, используя блокчейн как ещё один источник данных среди десятков других систем. Выбор между «строить» и «покупать» в этом контексте особенно важен.
Сравнивая подходы, полезно держать в голове несколько критериев.
– Скорость запуска: готовая on-chain data ingestion platform позволит выйти в прод за недели, а не месяцы.
– Гибкость: собственное решение позволяет учитывать любые специфические протоколы и кастомные smart‑контракты.
– Стоимость владения: подписка против постоянных затрат на инженеров, инфраструктуру и поддержку.
Обычно команды выбирают гибридную модель: базовая аналитика и популярные протоколы закрываются через внешний сервис, а всё, что связано с уникальными продуктами и конкурентным преимуществом, реализуется в собственной инфраструктуре. Такой подход снижает риски vendor lock‑in и позволяет масштабировать экспертизу внутри команды.
—
Real-world example: from zero to production dashboards
Представим условную команду аналитиков в финтех‑стартапе, который добавил поддержку крипто‑кошельков. В начале 2025 года у них нет ни одной on‑chain метрики, только агрегаты по внутренним переводам. Цель — через три месяца иметь прод‑дашборды с ежедневными отчётами по on‑chain активности клиентов, разбивкой по сетям и протоколам. Они решают начать с внешнего провайдера, которого считают best blockchain data provider for analysts по совокупности покрытия сетей и готовых схем. Это позволяет им быстро показать первые результаты и заручиться поддержкой руководства.
Дальше команда действует по шагам. Сначала формулируют ключевые KPI: доля on‑chain переводов в общем обороте, средний чек, концентрация активности на определённых протоколах. Затем разворачивают минимально необходимую инфраструктуру: хранилище в облаке, инструмент моделирования, пайплайны синхронизации с провайдером. Параллельно они строят reference‑layer по адресам клиентов, связывая внутренние учётные записи с on‑chain кошельками, и шаг за шагом разворачивают полноценные mart‑таблицы. К концу квартала у них уже есть несколько надежных витрин и систематический процесс backfilling при обновлении логики.
—
Forecast: where on-chain data ingestion is heading (2025–2030)
Сейчас, в 2025 году, on‑chain ingestion чем‑то напоминает web‑аналитику начала 2010‑х: много ручной работы, мало стандартов и большое разнообразие инструментов. В ближайшие пять лет ситуация почти наверняка изменится в сторону стандартизации и более глубокого слияния on‑chain и off‑chain данных. Уже сегодня крупные провайдеры стремятся стать универсальным слоем доступа к многим сетям сразу, а новые версии их платформ всё больше похожи на полноценные data‑стэки, а не просто APIs к нодам.
Есть несколько трендов, которые почти точно будут определять развитие темы до 2030 года.
– Унифицированные схемы и онтологии для основных типов on‑chain событий: swaps, loans, bridges, governance. Это уменьшит стоимость миграции между провайдерами и упростит обмен моделями между компаниями.
– Автоматизированная интерпретация смарт‑контрактов с помощью ML и статического анализа: аналитические платформы будут распознавать структуру протокола автоматически и генерировать базовые модели.
– Глубокая интеграция с enterprise‑стэком: on‑chain источники станут обычным «коннектором» в больших CDP, risk‑платформах и системах anti‑fraud.
Параллельно усилится фокус на конфиденциальности и регуляторике: появятся новые требования к хранению и обработке псевдонимных данных, а также к прозрачности алгоритмов кластеризации адресов. Это повлияет на дизайн ingestion‑пайплайнов: больше шифрования, строгие границы между слоями, формализованный аудит доступа. В результате успешные аналитические команды будут выглядеть как полноценные «on‑chain data operations» группы, которые умеют управлять полным циклом — от сырого блокчейн‑трафика до стратегических решений на уровне бизнеса.
—
Wrapping up
On‑chain data ingestion для аналитиков — это уже не эксперимент, а базовый навык 2025 года. Если упростить, вам нужно решить три ключевых задачи: понять свои бизнес‑вопросы, выбрать разумный баланс между внешними сервисами и собственной инфраструктурой, а затем аккуратно выстроить слои данных — от raw до метрик. При этом важно помнить, что блокчейн‑мир развивается быстрее, чем классические системы: контракты обновляются, появляются новые сети и форматы, меняются регуляторные требования. Поэтому пайплайн нужно строить так, чтобы его можно было эволюционировать без постоянных «переписываний с нуля».
Если подойти к теме системно — с чёткими определениями метрик, продуманной архитектурой и вниманием к качеству данных, — on‑chain аналитика перестаёт быть «магией разработчиков» и становится обычной, управляемой частью вашей data‑платформы. А значит, любой продуктовый или финансовый аналитик сможет уверенно работать с цепочкой блоков так же, как сегодня он работает с логами приложения или транзакциями в платежной системе.