
If you’re building anything serious on a blockchain in 2025, you’re almost never working with purely on-chain data. You’re stitching together on‑chain state, off‑chain APIs, analytics pipelines, and sometimes good old SQL databases. This tutorial walks through *how* to do that in practice and *why* today’s tooling looks the way it does.
—
From “code is law” to “code needs context”
Back in 2015–2017, Ethereum smart contracts mostly lived in their own bubble. The philosophy was simple:
– Deterministic execution
– No external calls that could break consensus
– No random numbers, no HTTP requests, nothing “from the outside world”
Developers hacked together workarounds: feeding data into contracts manually, hard‑coding parameters, or running private scripts. Not great.
By 2019–2021, DeFi exploded. Suddenly, protocols needed:
– Live price feeds
– Liquidation thresholds based on real‑time markets
– Cross‑chain message passing
– Verifiable randomness (lotteries, NFT drops, games)
That’s when blockchain oracle service for external data became an industry in itself. Chainlink started shipping production price feeds. Band Protocol, Pyth, Tellor, API3 and others joined the game.
Today, integrating on-chain data with external data sources isn’t an exotic trick. It’s standard architecture, supported by mature on-chain data integration tools, specialized indexers, and at least one web3 data integration platform in every serious stack.
—
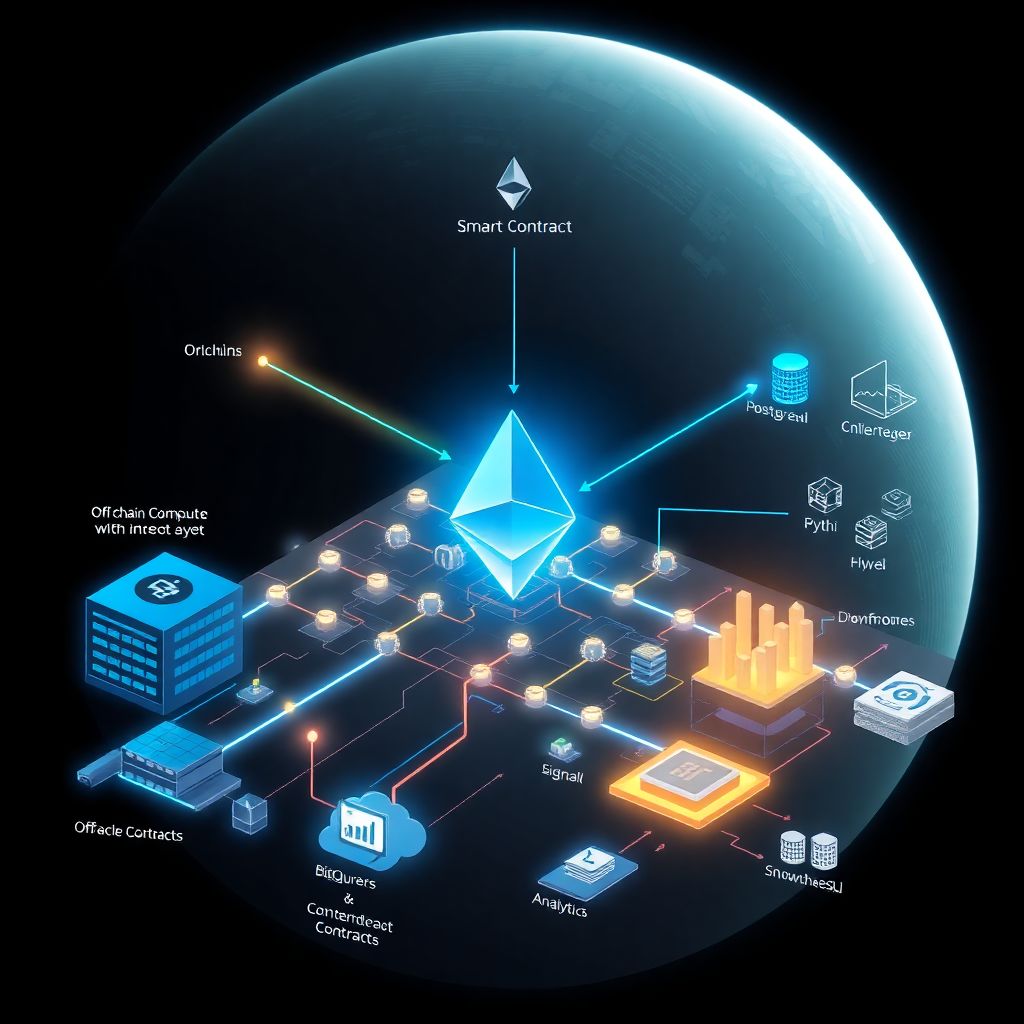
Core mental model: on‑chain, off‑chain, and the bridge
Whenever you ask *how to connect smart contracts to off-chain data*, think in three layers:
– Layer 1 – On‑chain: smart contracts, events, logs, merkle roots, proofs.
– Layer 2 – Off‑chain compute: indexers, backend services, data warehouses (PostgreSQL, BigQuery, Snowflake).
– Layer 3 – Bridge: oracles, relayers, APIs, messaging protocols that move data between 1 and 2.
Every integration pattern is basically:
“Read from A → Transform in B → Commit or verify in C.”
Let’s walk through concrete patterns with numbers, code, and war stories.
—
Pattern 1: Pulling external data into smart contracts via oracles

This is the classic case: your contract needs a price, weather data, a sports score, or a risk parameter that lives off‑chain.
In 2025, the usual flow looks like this:
1. You pick a blockchain oracle service for external data (e.g., Chainlink, Pyth, RedStone).
2. Your contract depends on an oracle interface.
3. Off‑chain providers push signed data to the oracle contracts.
4. Your contract reads the latest value during execution.
A minimal example (Chainlink‑style price feed):
“`solidity
// SPDX-License-Identifier: MIT
pragma solidity ^0.8.20;
interface AggregatorV3Interface {
function latestRoundData()
external
view
returns (
uint80 roundID,
int256 answer,
uint256 startedAt,
uint256 updatedAt,
uint80 answeredInRound
);
}
contract EthUsdConsumer {
AggregatorV3Interface public priceFeed;
constructor(address _feed) {
priceFeed = AggregatorV3Interface(_feed);
}
function getEthUsdPrice() external view returns (uint256) {
(, int256 answer,, uint256 updatedAt,) = priceFeed.latestRoundData();
// Simple sanity checks: data must be fresh and positive
require(answer > 0, “Invalid oracle price”);
require(block.timestamp – updatedAt < 30 minutes, "Stale price");
return uint256(answer);
}
}
```
Real‑world numbers, 2025 context
– Chainlink reports securing $25B+ in DeFi TVL across chains.
– Pyth price feeds serve hundreds of protocols with sub‑second latencies on some chains.
– On Ethereum mainnet, a single oracle read is typically < 30k gas, while a write from oracle nodes is more expensive but amortized across users.
This pattern is perfect when:
– You only need a *current* value (e.g., ETH/USD price, BTC volatility index).
– Users must be able to verify the value on-chain without trusting your server.
– Latency in the range of 10–60 seconds is acceptable.
—
Pattern 2: Indexing on‑chain data into external databases
Most analytics, dashboards, and business logic don’t run inside the blockchain. They sit on:
– ClickHouse clusters,
– Postgres databases,
– Data warehouses like BigQuery, Snowflake, or Redshift.
The typical pipeline for API for integrating blockchain with external databases today:
1. A node or node provider (e.g., Alchemy, Infura, Ankr) streams blocks and logs.
2. An indexer parses transactions, events, traces.
3. Parsed data is stored in relational or columnar databases.
4. Your backend or BI tools query this database via REST/GraphQL/SQL.
You can use managed solutions like The Graph, Subsquid, Covalent, or roll your own.
Example indexing flow with a custom service:
“`bash
Pseudo-steps for a minimal indexer
1. Connect to Ethereum node via WebSocket
2. Subscribe to “Transfer” events for your ERC-20
3. For each event:
– Decode “from”, “to”, “value”
– Insert into Postgres table “transfers”
4. Expose REST API /api/transfers?address=0x… backed by SQL
“`
On the SQL side:
“`sql
SELECT
block_number,
tx_hash,
“from”,
“to”,
value
FROM erc20_transfers
WHERE “from” = $1 OR “to” = $1
ORDER BY block_number DESC
LIMIT 100;
“`
This is what sits behind a lot of “portfolio” pages and analytics dashboards. Dune, Flipside, Nansen and others basically operate high‑throughput web3 data integration platform stacks at scale, ingesting billions of events.
—
Pattern 3: Smart contracts <→ your backend, safely
Sometimes you don’t need a public oracle network. You just want your own backend to talk to your own contracts.
Practical use cases:
– A game server determining match results and posting them on‑chain.
– A KYC provider setting a “verified” flag for user wallets.
– A SaaS billing system marking invoices as paid based on blockchain receipts.
The naive way: your backend holds a private key and directly sends transactions to your contracts. That’s fine *if* you manage keys correctly and understand the trust assumptions.
Flow:
1. User performs some action in your web/app UI.
2. Your backend validates business logic off‑chain (could query your SQL DB + chain state).
3. Backend sends a signed transaction calling a restricted function on the contract.
4. Contract enforces that only your backend’s address can call it.
Example Solidity snippet:
“`solidity
pragma solidity ^0.8.20;
contract KYCRegistry {
address public admin; // Backend signer
mapping(address => bool) public isVerified;
constructor(address _admin) {
admin = _admin;
}
function setVerified(address user, bool verified) external {
require(msg.sender == admin, “Only backend”);
isVerified[user] = verified;
}
}
“`
Then in Node.js:
“`ts
import { ethers } from “ethers”;
async function markVerified(userAddress: string, verified: boolean) {
const provider = new ethers.JsonRpcProvider(process.env.RPC_URL);
const wallet = new ethers.Wallet(process.env.ADMIN_PK!, provider);
const contract = new ethers.Contract(KYC_REGISTRY_ADDRESS, ABI, wallet);
const tx = await contract.setVerified(userAddress, verified);
await tx.wait(1); // wait for inclusion
}
“`
Security note: if `ADMIN_PK` leaks, anyone can “verify” arbitrary addresses. So use HSMs, KMS (AWS/GCP), and role separation.
—
Pattern 4: Verifiable off‑chain computation
The newer wave of tools in 2023–2025 is about doing heavy computation off‑chain and posting a *proof* on‑chain:
– zk‑rollups and validity proofs
– Optimistic rollups (with a challenge window)
– Verifiable computation frameworks (RiscZero, zkSync’s ZK Stack, Starknet tooling)
Instead of writing “all the logic” on a monolithic L1, you do:
1. Gather on‑chain data (state roots, events).
2. Compute results off‑chain (for example, a batch of 10,000 trades).
3. Generate a proof that the computation followed predefined rules.
4. Submit the proof and a result hash to L1.
5. Smart contract verifies the proof, usually in a few hundred thousand gas.
This is still integrating on-chain data with external data sources, just with a cryptographic guarantee instead of social trust. For more complex systems, you’ll see hybrid flows:
– Off‑chain data (e.g., order book snapshots)
– Combined with on‑chain state (balances, positions)
– Verified by a zk proof on mainnet or a settlement chain
—
Hands‑on: integrating on‑chain data with external data sources
Let’s walk through a realistic mini‑project you might ship in 2025:
> A lending dashboard that:
> – shows user positions and liquidation risk from the chain
> – enriches with fiat prices from oracles
> – stores everything in Postgres for history and analytics
Step 1. Read on‑chain positions
Assume your protocol emits a `PositionUpdated` event:
“`solidity
event PositionUpdated(
address indexed user,
uint256 collateral,
uint256 debt,
uint256 timestamp
);
“`
You run an indexer that listens for this event and writes to `positions` table:
“`sql
CREATE TABLE positions (
user_address BYTEA NOT NULL,
collateral NUMERIC(38, 18) NOT NULL,
debt NUMERIC(38, 18) NOT NULL,
block_number BIGINT NOT NULL,
tx_hash BYTEA NOT NULL,
updated_at TIMESTAMPTZ NOT NULL
);
“`
Step 2. Fetch oracle prices periodically
Every 15 seconds, your service reads ETH/USD from an oracle contract and persists it:
“`ts
async function fetchEthUsdPrice() {
const provider = new ethers.JsonRpcProvider(process.env.RPC_URL);
const feed = new ethers.Contract(FEED_ADDR, FEED_ABI, provider);
const [, answer,, updatedAt] = await feed.latestRoundData();
if (Date.now() / 1000 – Number(updatedAt) > 60) {
throw new Error(“Price feed is stale”);
}
return Number(answer) / 1e8; // assuming 8 decimals
}
“`
You store it in a `prices` table:
“`sql
INSERT INTO prices (symbol, value, source, observed_at)
VALUES (‘ETH-USD’, $1, ‘chainlink’, NOW());
“`
Step 3. Build an internal API that joins on‑chain and off‑chain
Now your frontend calls your backend, not the chain directly. The backend exposes something like:
“`http
GET /api/user/:address/health
“`
Implementation sketch:
“`ts
async function getUserHealth(address: string) {
const client = await pgPool.connect();
const [{ collateral, debt }] = await client.query(
“SELECT collateral, debt FROM positions WHERE user_address = $1 ORDER BY updated_at DESC LIMIT 1”,
[Buffer.from(address.slice(2), “hex”)]
);
const [{ value: ethUsd }] = await client.query(
“SELECT value FROM prices WHERE symbol = ‘ETH-USD’ ORDER BY observed_at DESC LIMIT 1”
);
const collateralUsd = collateral * ethUsd;
const healthFactor = collateralUsd / debt; // naive example
return { collateralUsd, debt, healthFactor };
}
“`
This is a textbook example of API for integrating blockchain with external databases: your REST API is the surface, but under the hood it marries on‑chain events with price feeds and SQL.
—
Choosing the right on-chain data integration tools in 2025
To avoid reinventing the wheel, you’ll typically combine several categories of tooling:
– Node providers: Alchemy, Infura, QuickNode, Ankr
– Indexers & subgraph frameworks: The Graph, Subsquid, Covalent, Goldsky
– Oracles: Chainlink, Pyth, RedStone, API3
– Analytics platforms: Dune, Flipside, Nansen, Footprint
– Message/bridge layers: LayerZero, Wormhole, Hyperlane
When people talk about on-chain data integration tools generically, they usually mean some mix of:
– A standardized way to parse logs and normalize schemas
– A convenient query layer (GraphQL, SQL, REST)
– A stable API and SLA, so you don’t maintain your own full node farm
Modern web3 data integration platform offerings often expose:
– Webhooks when certain events fire on‑chain
– Reverse‑indexed address usage (e.g., “all NFTs owned by X”)
– Rate‑limited but predictable APIs suitable for production usage
—
How to connect smart contracts to off-chain data without shooting yourself in the foot
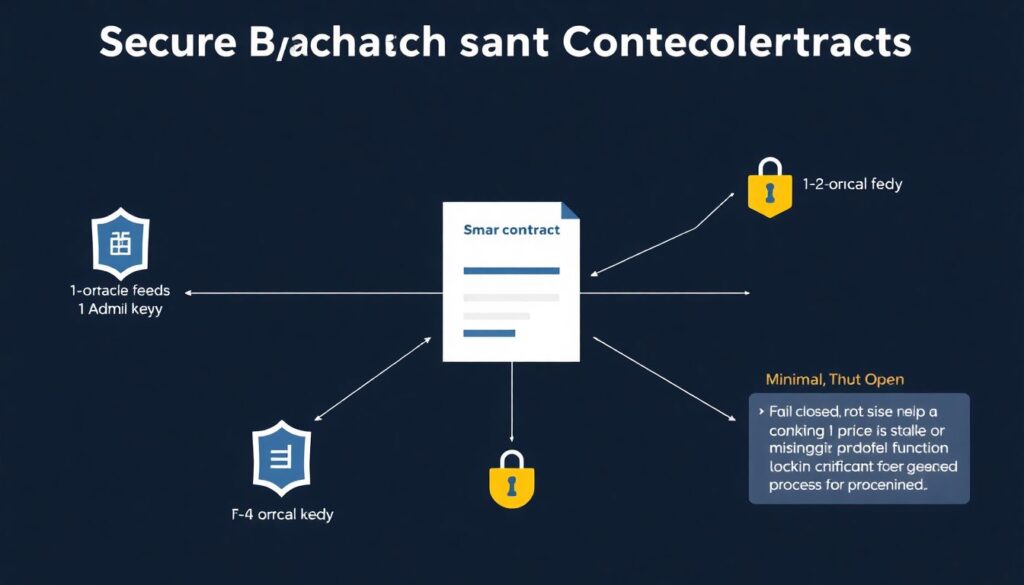
Some battle‑tested guidelines:
– Minimize trust surface
Let your contracts depend on a *small number* of external inputs:
– 1–2 oracle feeds,
– 1 admin key,
– 1 governance process.
– Fail closed, not open
If a price feed is stale or missing, revert or freeze sensitive functionality instead of guessing.
– Emit events for everything
When an external source affects state (e.g., your backend calling `setVerified`), emit detailed events. This gives you observability and downstream indexing for free.
– Monitor oracles aggressively
Track:
– Update frequency
– Deviation between multiple feeds (e.g., Chainlink vs Pyth)
– Outliers relative to centralized exchanges
– Simulate failure modes
Regularly simulate:
– Oracle stopped updating for 1 hour
– Oracle sends 50% wrong price
– Backend signer rotated or compromised
This is where many integrations break under stress.
—
Historical arc: from cron jobs to verifiable data flows
The early pattern (2016–2018) was hilariously crude:
a cron job read some HTTP API, signed a transaction with a hot wallet, and pushed “data” on-chain. No redundancy, no proofs, no committee.
By 2020, projects started using official oracle networks, but a lot of internal stuff (rewards, scoring, KYC) still ran on private servers with opaque logic.
In 2023–2025, three big shifts happened:
1. Standardization of oracle interfaces
Most EVM chains now offer almost drop‑in compatible price feed interfaces, making migrations and multi‑chain deployments much easier.
2. Explosion of data‑centric infra
Off‑the‑shelf indexers, managed subgraphs, and data APIs mean teams can go from “new protocol” to “usable analytics dashboard” in days, not months.
3. Rise of verifiable computation
Zero‑knowledge proofs moved from academic prototypes to production in rollups, privacy layers, and specialized zk services, reducing how much logic must live on L1.
The net result: integrating on-chain data with external data sources in 2025 is less about “is it possible?” and more about “what’s the right trade‑off between trust, cost, and complexity for this specific use case?”
—
Putting it all together in your next project
When you design a new dApp today, sketch the integration plan up front:
– Which data absolutely must be on-chain and verifiable?
– Which data is fine to keep in an external DB with audit trails?
– Where do you need oracles vs. a private backend?
– Do you foresee needing zk proofs or rollup‑style batching?
Then choose:
– An oracle network for prices / external signals.
– An indexer or subgraph to mirror chain state into a queryable store.
– A backend API that fuses chain data, your own business logic, and external systems.
If you respect the consensus boundaries, carefully manage trust assumptions, and test your failure modes, on-chain data integration tools plus today’s infra make these hybrid architectures not just possible, but straightforward to maintain.
That’s the real evolution from early smart contracts to 2025: smart contracts stopped pretending to be the whole system and became the *verification and settlement layer* in a much richer data ecosystem.