
Why a Crypto Analytics Pipeline Matters More Than Ever
Before diving into the “how”, it helps to understand *why* a proper crypto analytics pipeline is worth your time. Crypto markets move fast, are mostly API‑first, and generate insane volumes of on‑chain and off‑chain data. If вы просто скачиваете CSV из биржи и иногда обновляете график в Excel, вы неизбежно будете опаздывать и принимать решения вслепую. Настроенный конвейер данных позволяет вам системно собирать, очищать и анализировать информацию, а не охотиться за ней в последний момент. Хорошая crypto analytics platform for investors превращает хаотичный поток котировок, ордербуков и транзакций в понятные сигналы: где растёт риск, где появляется ликвидность, когда рынок становится перегретым. Это не магия и не привилегия только хедж‑фондов; это просто последовательность шагов, которую можно повторить в упрощённом виде даже в одиночку, если понимать архитектуру процесса.
Step 1. Choosing and Combining Data Sources
On‑chain vs off‑chain: что именно вы измеряете
Самая частая ошибка новичков — пытаться «взять все данные сразу». На практике начинать лучше с чёткого ответа на вопрос: вы анализируете поведение цены, активность пользователей или инфраструктуру сети? Off‑chain данные (котировки, ордербуки, фьючерсы, опционы, funding rates, новости) помогают понимать, как торгуют рынки, кто давит цену и где скапливается открытый интерес. On‑chain данные (транзакции, балансы кошельков, объёмы мостов, активность смарт‑контрактов) показывают реальное движение капитала в сети. Для trading‑стратегий логично комбинировать эти источники, но сначала определите приоритет, иначе вы утонете в API и будете больше заниматься интеграциями, чем анализом.
Как выбирать поставщиков данных без разочарований
Когда вы начинаете строить свой конвейер, слишком легко поддаться маркетингу и выбрать сервис по первому красивому дэшборду. Лучше подходить к выбору как к техническому продукту. Лучшие best crypto data providers for quantitative analysis дают полную документацию, стабильные SLA по аптайму API, прозрачную политику лимитов и историю изменений схемы данных. Обязательно посмотрите, как быстро обновляется информация, есть ли поддержка исторических данных глубиной хотя бы в несколько лет и насколько легко масштабировать запросы. Не полагайтесь только на «бесплатные» источники: они пригодны для прототипа, но при росте объёмов начнут лимитировать скорость и ломать ваши отчёты в самый неподходящий момент.
Практический минимум для старта
Чтобы не растягивать первый этап на месяцы, соберите базовый набор источников, который покроет большинство сценариев. Как правило, это: API одной‑двух крупных централизованных бирж с глубокой историей и деривативами; on‑chain провайдер с нормальной поддержкой логов и декодированием событий для основных сетей; ценовой агрегатор, который даёт унифицированные фиды по множеству пар; что‑то вроде on-chain data analytics tools for crypto trading с уже готовыми метриками по активным адресам и потокам в/из бирж. Такой набор позволит строить как простые индикаторы (объём + волатильность), так и продвинутые сигналы по притокам и оттокам капитала, не тратя недели на ручную обработку сырых блокчейн‑логов.
Step 2. Ingestion: Getting Data Reliably into Your System
Поток vs батч: не пытайтесь сделать всё real‑time сразу
Слово «real‑time» звучит привлекательно, но часто излишне усложняет архитектуру на старте. Для большинства задач анализа достаточно обновлять данные раз в минуту или даже реже. Реальные real-time crypto market analytics software решения используют стриминг, WebSocket‑подключения, очереди сообщений и масштабируемые консьюмеры, но вы можете начать с батч‑загрузки каждые N минут через обычный REST‑API. Важно не то, насколько это «современно», а насколько надёжно и воспроизводимо: скрипт, который стабильно тянет свечи и ордербуки по расписанию, лучше неустойчивого стриминга, который падает при каждом сетевом глюке и оставляет пробелы в истории.
Технический каркас загрузки
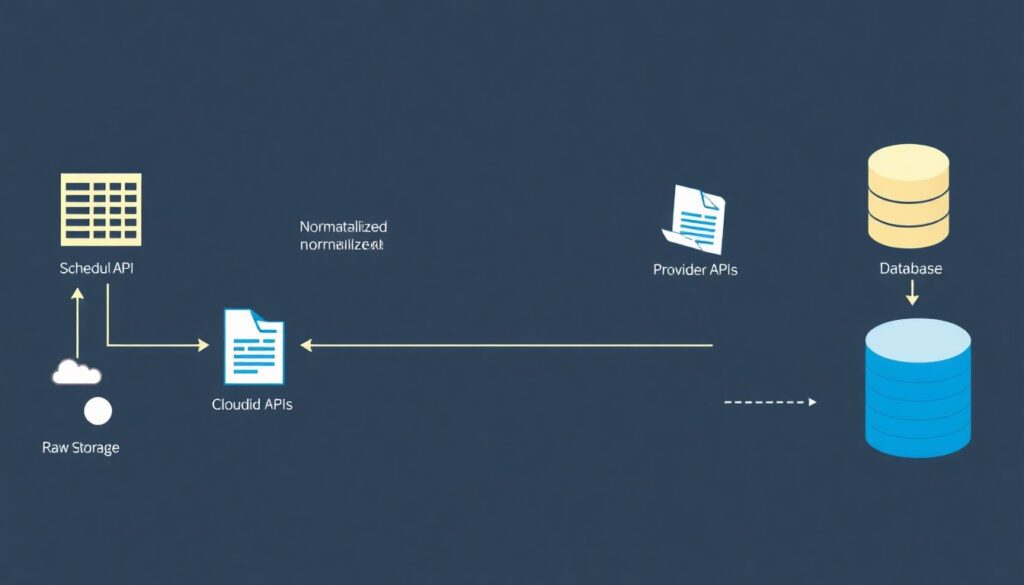
Минимально рабочая схема приёма данных выглядит так: планировщик (cron, Airflow, аналог) вызывает скрипты, которые ходят в API поставщиков, сохраняют сырые ответы в хранилище (облако или локальный диск) и только потом кладут нормализованные данные в базу. Это кажется избыточным, но сохранять «сырую копию» — критично: при ошибках в обработке можно перепарсить файлы, а не стягивать всё с нуля. Для блокчейна отдельное внимание уделите ограничению запросов: если вы не будете отслеживать последний обработанный блок и корректно продолжать с него, рискуете либо дублировать события, либо пропускать их при сбоях соединения. Логирование и простая система алертов (например, уведомление, если задержка данных превысила 5 минут) избавят вас от неприятных сюрпризов при запуске торговых стратегий.
Типичные ошибки на этапе ingestion
Новички часто совершают три одинаковых промаха: игнорируют лимиты API, не продумывают ретраи и не версионируют схемы. Когда биржа внезапно меняет формат ответа, весь ваш парсер рушится, а вы об этом узнаёте только через пару дней по дыре в данных. Чтобы этого не случилось, добавьте простую валидацию: проверяйте, что в ответе есть ожидаемые поля, а формат даты не изменился. При ошибке логируйте тело ответа и сохраняйте его в отдельное хранилище. Не забывайте и о тестовой среде: хотя бы один «песочний» инстанс пайплайна, который крутится на меньшем объёме и позволяет безопасно пробовать новые версии кода без риска повредить основной поток данных.
Step 3. Storage: Structuring Data so You Can Actually Use It
От сырых логов к аналитическому хранилищу
Сохранить данные — половина дела; гораздо сложнее сделать так, чтобы через месяц вы могли быстро из них что‑то посчитать. Для этого имеет смысл разделить хранилище на уровни: raw (как пришло от поставщика), cleaned (исправленные форматы, таймзоны, дубликаты) и curated (агрегированные таблицы под конкретные задачи — свечи, базовые on‑chain метрики, деривативные индикаторы). Такая иерархия снимает напряжение: вы знаете, что любые странности в отчётах сначала нужно искать в верхнем уровне, а не ковырять каждую ступень загруженного конвейера. Не экономьте на метаданных: логируйте источники, время загрузки, версии схем — это поможет выяснить, почему показатель за прошлую неделю внезапно пересчитался.
Выбор хранилища под ваши объёмы и задачи
Для первых экспериментов подойдёт даже SQL‑база, но по мере роста истории и числа бирж она начнёт тормозить. Если планируются сложные аналитические запросы, лучше сразу думать в сторону колоночных хранилищ и облачных аналитических сервисов. Особенно это важно, если вы хотите разворачивать blockchain data pipeline solutions for exchanges уровня, где спектр запросов идёт от простых репортов объёмов до проверки подозрительных транзакций по большому числу адресов. Для ончейн‑истории отдельный вызов — размер: полный архив Ethereum занимает терабайты, и здесь логичнее полагаться на специализированных провайдеров или сервисы с уже индексированными событиями, чем пытаться поднимать собственный full node без понятной окупаемости.
Советы по надежности и экономии
Чтобы не переплачивать за хранение, заранее продумайте политику «старения» данных. Сырые логи через какое‑то время можно отправлять в более дешёвое хранилище, сохраняя быстрый доступ только к агрегированным срезам за последние месяцы. Регулярные бэкапы — не формальность, а обязательный ритуал: потеря истории ломает не только отчёты, но и возможность переобучать модели и проверять гипотезы. Для небольших команд хорошей практикой будет хранить скрипты миграций и схемы в одном репозитории с кодом пайплайна: так изменения в структуре данных всегда связаны с изменениями в логике обработки, и меньше шансов, что кто‑то случайно повредит важные таблицы.
Step 4. Transformation: Turning Raw Data into Usable Metrics
Нормализация и очистка как защита от ложных сигналов
Подавляющее большинство проблем с аналитикой связано не со сложностью моделей, а с грязными данными. Разные биржи могут использовать разные таймзоны и точность цены, токены могут менять тикеры, а stablecoin с «одинаковым» названием на разных цепочках — это совсем не одно и то же. На этапе трансформации задача — привести формат к единому стандарту: нормализовать временные метки, унифицировать активы по внутреннему идентификатору, убрать дубликаты и аномальные значения (например, свечи с нереалистичным спредом или нулевым объёмом в период высокой волатильности). Это не самый эффектный этап, но именно здесь вы снимаете риск «фантомных» аномалий, которые на самом деле являются ошибкой в данных.
Строительство метрик и индикаторов
Когда базовая чистка сделана, можно переходить к разработке конкретных метрик под ваши сценарии. Для трейдинга это могут быть объёмы спотовых и деривативных сделок, концентрация ликвидности по ценовым уровням, соотношение длинных и коротких позиций, показатели волатильности. На ончейн‑стороне — активные адреса, величина холдингов крупных кошельков, скорость роста или сжатия TVL в протоколах, замеры по мостам и обменникам. Здесь как раз начинают работать on-chain data analytics tools for crypto trading: вместо того чтобы вручную высчитывать базовые вещи, вы можете использовать готовые фреймворки и дополнять их своими идеями. Главное — документировать каждую метрику: как она считается, из каких таблиц берётся, с какой частотой обновляется и где применяются фильтры.
Частые ошибки при построении показателей
Распространённая ловушка — путать корреляцию и причинность. То, что рост активных адресов совпал с ростом цены, ещё не значит, что одно вызвало другое. Ещё одна проблема — «обучение на тесте»: когда вы подбираете метрики, идеально описывающие уже известный вам период, они могут полностью провалиться на новых данных. Чтобы этого избежать, разделяйте временные диапазоны на train/validation/test, даже если вы не строите сложные ML‑модели. Наконец, не пренебрегайте банальной визуальной проверкой: многие странности в индикаторах заметны сразу на графике, но плохо видны в таблице чисел.
Step 5. Analytics & Modeling: Extracting Signals and Insights
От простых срезов к системным гипотезам
На этом этапе появляется соблазн сразу прыгнуть в нейросети и сложный квантовый анализ. В реальности начните с обычной описательной аналитики: распределения, соотношения, динамика во времени, сравнение сегментов. Такие шаги уже способны выявить базовые паттерны: какие биржи дают наибольший вклад в объём, какие активы чаще всего выступают в роли «лидирующих индикаторов», какие когорты пользователей наиболее склонны к «горячим» сделкам. Постепенно формулируйте гипотезы: например, что скачок притоков на биржи предшествует росту волатильности, или что определённые комбинации funding rate и open interest указывают на риск массовой ликвидации.
Использование статистики и машинного обучения
Когда гипотезы сформированы, вы можете переходить к проверке через статистические тесты и модели. Для торговых стратегий полезны регрессии, которые оценивают вклад разных факторов в доходность, а также классификаторы, пытающиеся заранее предсказать режим рынка (трендовый, боковой, высоко‑волатильный). Несложные модели часто дают более надёжные результаты, чем «чёрные ящики», потому что их проще интерпретировать и пересматривать при смене рыночного режима. Подходящие on-chain и off‑chain наборы признаков в сочетании с аккуратно выбранным горизонтом прогноза дают лучшее соотношение риска и сложности, чем бездумное масштабирование числа фичей и глубины моделей.
Типичные ловушки при моделировании
Классическая ошибка — переоптимизация под историю: вы крутите параметры до тех пор, пока кривая доходности в прошлом не станет красиво восходящей. В реальном времени такая система разваливается при первом же нетипичном событии. Чтобы бороться с этим, используйте walk‑forward тестирование, регуляризацию и жёсткие ограничения на сложность модели. Не забывайте о транзакционных издержках, проскальзывании и задержках при исполнении — многие «идеальные» стратегии рушатся, как только добавить реалистичные параметры комиссии и ликвидности. И, наконец, следите за изменением качества моделей во времени: если метрики на валидации системно ухудшаются, это сигнал, что структура рынка изменилась и требуется переобучение или пересмотр гипотез.
Step 6. Visualization and Decision Support
От дэшбордов к реальным решениям
Дэшборды сами по себе не создают альфу, но превращают сложные расчёты в понятные истории. В идеале каждый экран должен отвечать на конкретный вопрос: «сколько мы зарабатываем на этой стратегии», «где сейчас накапливается риск», «какие активы ведут себя аномально относительно бенчмарка». Хорошая crypto analytics platform for investors не перегружает пользователя лишними графиками, а акцентирует внимание на ключевых сигналах и даёт возможность drill‑down до исходных данных при необходимости. Если вы строите систему для себя, начните с трёх‑четырёх критичных виджетов и только потом наращивайте детали, чтобы не отвлекаться от реальных решений ради эстетики интерфейса.
Настройка алертов и интерактивных элементов
Помимо статических отчётов многие команды недооценивают силу продуманной системы оповещений. Автоматические сигналы о выходе метрик за заданные пороги — будь то рост ончейн‑активности, скачок волатильности или аномальное расхождение котировок между биржами — позволяют реагировать, пока ещё есть время. Важно, однако, избежать «шума»: если алерты срабатывают слишком часто или по слабым сигналам, пользователи их просто игнорируют. Планируйте систему уровней — мягкие уведомления для наблюдения и жёсткие триггеры для реального реагирования. Интерактивность (фильтры по биржам, активам, временным диапазонам) помогает оперативно проверять гипотезы прямо в интерфейсе, не залезая каждый раз в код.
Ошибки в визуализации и интерпретации
Неочевидная, но опасная ошибка — искажённые оси и некорректные сравнения. Например, сравнение показателей с разными масштабами без нормализации создаёт иллюзию сильных сдвигов там, где изменений почти нет. Выбор слишком сглаженных интервалов (дневные вместо минутных) легко скрывает краткосрочные всплески риска. Визуализации должны помогать, а не манипулировать: избегайте излишней цветовой нагрузки, используйте понятные подписи и всегда давайте пользователю доступ к описанию метрик, чтобы не приходилось догадываться, что именно означает та или иная линия на графике.
Step 7. Operational Aspects: Reliability, Governance, and Scaling
Мониторинг пайплайна как часть аналитики
Продуктивная система аналитики — это не только модели и дэшборды, но и здоровье самого конвейера. Отсутствие мониторинга приводит к тому, что вы принимаете решения на основе устаревших или частично загруженных данных. Настройте базовые метрики: задержка от реального времени до появления данных в хранилище, частота ошибок при обращении к API, доля успешных задач за сутки. Когда вы строите серьёзные blockchain data pipeline solutions for exchanges или крупных фондов, эти показатели становятся такими же важными, как и PnL. Автоматическая блокировка торговых действий при определённых сбоях в пайплайне часто выглядит строго, но на практике защищает от дорогостоящих ошибок.
Управление доступом и качеством данных
По мере роста команды количество людей, меняющих код и данные, растёт. Без минимальной дисциплины вы быстро получите хаос: две версии одной метрики, три конкурирующих источника истины, неоднозначные названия таблиц. Решается это через понятные правила: единый каталог метрик и источников, код‑ревью любых изменений в трансформациях, разделение прав на чтение и запись. Для критичных наборов данных полезно иметь процесс «data quality check» перед использованием в моделях или отчётах: автоматические тесты, проверяющие отсутствие пропусков, неожиданных всплесков или нулевых значений там, где их быть не должно. Это выглядит бюрократично, но экономит часы расследований и спасает от неверных решений.
Масштабирование без переписывания всего с нуля
В какой‑то момент объёмы исторических данных, число подключенных бирж и сетей, а также спрос на отчёты вырастут настолько, что текущая инфраструктура начнёт тормозить. Важно заранее закладывать архитектуру, которую можно горизонтально расширять: разбивать пайплайн на независимые компоненты, использовать очереди для связи между ними, хранить конфигурацию и параметры отдельно от кода. Тогда переход, например, от одной базы к более мощному хранилищу или от одиночного сервера к кластеру будет болезненным, но не смертельным. Для начинающих полезно придерживаться простого принципа: сначала сделайте маленькую, но модульную систему, а не монолитный «скрипт на все случаи жизни».
Practical Tips for Beginners: How to Start Without Overwhelm
Упрощённый маршрут: от идеи до первых инсайтов за пару недель
Многим кажется, что полноценная аналитическая система требует команды инженеров и месяцев разработки. На самом деле можно начать намного проще. Сначала выберите одну биржу и один‑два ончейн‑источника, которые вы понимаете. Затем напишите небольшие скрипты для регулярной выгрузки ключевых данных: свечи, объёмы, базовые ончейн‑метрики. Сохраните всё в доступное хранилище и сфокусируйтесь на одной‑двух гипотезах: например, как изменяется ликвидность вокруг крупных новостей или как ончейн‑притоки влияют на волатильность. Добавьте минимальный дэшборд, где вы можете визуально отслеживать эти показатели. После этого постепенно расширяйте покрытие, не забывая автоматизировать рутинные шаги.
- Начните с одного рынка и ограниченного набора метрик, чтобы не утонуть в данных.
- Выбирайте инструменты, которые сможете поддерживать сами, а не только «самые модные».
- Обязательно документируйте источники и формулы, даже если работаете в одиночку.
Чего избегать на первых этапах
Не пытайтесь сразу построить «идеальную» систему, покрывающую все цепочки и все биржи. Такая амбиция быстро превратится в технический долг и отнимет время у реального анализа. Осторожно относитесь к сложным моделям: без устойчивого пайплайна данных и проверенных метрик даже лучший алгоритм будет выдавать мусор. Не поддавайтесь соблазну слепо копировать чужие дэшборды и индикаторы; лучше понять, какие вопросы вы реально хотите решать, и адаптировать инструменты под себя. И, конечно, не стоит полагаться только на одну real-time crypto market analytics software панель: комбинируйте оперативные сигналы с более глубоким, медленным анализом трендов и рисков.
- Не масштабируйте инфраструктуру раньше, чем вам станет тесно в текущей.
- Не пренебрегайте простыми sanity‑чеками на каждом этапе конвейера.
- Не забывайте, что рынок меняется, и любые модели требуют периодического пересмотра.
Как оценить, что пайплайн работает «достаточно хорошо»
Готовность системы определяется не количеством модных инструментов, а тем, насколько она помогает принимать решения. Признаки здорового конвейера довольно просты: вы можете быстро ответить на ключевые вопросы по своему рынку, отслеживать изменения в разумные сроки и уверены, что данные за последние дни не отличаются по качеству от истории. Если добавление нового источника или метрики не превращается в катастрофу, а занимает предсказуемое время, значит архитектура выбрана удачно. В такой среде любые дальнейшие улучшения — от сложных моделей до интеграции с торговыми системами или расширения до полноценной crypto analytics platform for investors — становятся естественным развитием, а не болезненным скачком.