

Why Crypto Researchers Need Automated Data Quality Checks in 2025
If you do serious crypto research and you’re still validating data manually, you’re not “being careful” — you’re just being slow and exposed to hidden errors.
The good news: most critical data quality checks can be automated with a mix of scripts, dashboards and modern crypto data quality tools. Below is a step‑by‑step framework you can actually implement, with common pitfalls and practical advice for newer researchers.
—
Step 1. Standardize Your Raw Data Before You Trust Anything
Normalize the chaos
On‑chain and market feeds are messy by design:
– Different timestamp formats
– Varying decimal precision
– Token symbols reused across chains
– Incomplete or delayed price feeds
Before you feed anything into your crypto trading data analysis platform, enforce a strict schema and normalization layer.
What to automate
– Timestamps
– Convert everything to UTC. No discussion.
– Strip milliseconds unless you genuinely do high‑frequency work and your source is accurate enough to justify them.
– Add a “source_latency_ms” field when possible (exchange APIs often give server times; measure round‑trip yourself).
– Numeric formats
– Normalize all prices to `float`/`decimal` with consistent precision (e.g. 8 or 10 decimals).
– Normalize volumes and balances to base units and store original units as metadata.
– Token identity
– Map everything to a canonical token ID (e.g. contract address + chain ID), not just ticker.
– Keep a registry of known conflicts: same ticker, different asset.
Newbie warning
If you merge two datasets only by symbol and timestamp, at some point you’ll mix:
– Wrapped vs native assets (e.g. WETH vs ETH)
– Synthetic assets vs spot
– Multiple chains with the same symbol
Automate checks that fail loudly when:
– The same ticker maps to multiple contract addresses in one chain.
– A contract address maps to multiple tickers in the same time window.
—
Step 2. Validate Source Integrity and Coverage
Don’t assume the feed is “complete enough”
Missed candles and silent gaps are the classic way to ruin backtests and protocol analytics. In 2025, automated crypto data validation should always include explicit coverage checks.
What to automate
– Continuity checks for time series
– For each market / pair, verify that all expected intervals exist (e.g. every 1m or 1h candle).
– Flag and log:
– Missing intervals
– Duplicate timestamps
– Overlapping candles
– Source cross‑checks
– Compare OHLCV from at least two data providers for the same pair.
– Define tolerances (e.g. price differences > 0.5% or volume differences > 5% for liquid pairs).
– Auto‑label outliers as “suspect” but don’t auto‑delete; route them to a review queue.
– Schema drift detection
– Automatically monitor JSON/CSV field structures from APIs.
– If an exchange silently adds/removes/renames fields, your pipeline should alert, not just fail downstream.
Mistakes to avoid
– Trusting “reliable” exchanges blindly. Even top venues push bad candles and retroactively fix them.
– Ignoring weekends and holidays; in crypto there is no market close. If you see gaps, they’re almost always data problems, not trading halts.
—
Step 3. Run Value Range and Sanity Checks on Prices & Volumes
Sanity beats sophistication
You don’t need advanced crypto market data analytics software to catch the worst outliers — simple automated rules remove most garbage.
What to automate
– Price range sanity
– Reject or quarantine candles where:
– `low > high`
– `open` or `close` lies far outside `[low, high]`
– Absolute price jumps exceed a threshold (e.g. > 50% in one minute for large caps).
– Use adaptive thresholds: stricter for BTC/ETH, looser for microcaps.
– Volume anomalies
– Track 7‑day rolling median and standard deviation of volume.
– Flag:
– Volume spikes > N standard deviations above rolling mean
– Entire days with *zero* volume on historically active pairs
– Internal consistency
– For order book data, enforce: `best_bid <= best_ask`.
- For trades: prices should fall within contemporary bid‑ask spreads.
Newbie tip
Don’t automatically discard every anomaly. Mark it, tag it, and store why it was flagged. Sometimes anomalies are exactly what you want to study (e.g. liquidations, oracle attacks, major listings).
—
Step 4. Handle Duplicates, Gaps, and Revisions Systematically
Blockchain is immutable; your dataset isn’t
Reorgs, provider bugs and backfills mean your historical data will be revised. If you don’t model this explicitly, your research will quietly diverge from reality.
What to automate
– Duplicate detection
– For trades: deduplicate by `(exchange_id, pair, trade_id)` or a strong hash over `(timestamp, side, price, size)`.
– For blockchain data: deduplicate by `(chain_id, block_number, tx_hash, log_index)`.
– Gap handling
– When continuity checks (from Step 2) detect missing windows, try:
– Automatic backfill from a secondary provider
– Re‑querying the primary API for that slice
– Annotate the data with a “backfilled” flag.
– Revision tracking
– Version your datasets. If a provider rewrites historical OHLCV, keep both versions with metadata on import time and source.
– Your models should be able to reproduce “what was known at time T” vs “final corrected history”.
Common trap
Using yesterday’s export as “ground truth” and overwriting it with today’s updated export. You lose the history of corrections and can’t debug model drift later.
—
Step 5. On‑Chain Data: Schema, Decoding, and Cleansing
ABI errors hurt more than missing rows
In DeFi, one wrong event decoding rule is worse than losing 10% of events — you get perfectly structured, wrong data.
This is where dedicated blockchain data cleansing solutions and parsers pay off.
What to automate
– ABI validation
– Automatically verify that event signatures in your code match on‑chain logs.
– Alert when the number or types of indexed/non‑indexed fields in logs diverge from your schema.
– Contract upgrades and proxies
– Maintain a registry mapping proxy contracts to implementation contracts and versions.
– When implementation changes, your decoding logic must update simultaneously.
– Auto‑detect ABI mismatches as soon as a new implementation goes live.
– Dedup and classify on‑chain events
– Group related events per transaction: swaps, adds/removes of liquidity, liquidations, liquid staking events, etc.
– For multi‑call transactions, enforce deterministic ordering of events for reproducible analysis.
Warning for new researchers
If you download a “DeFi dataset” from a public repo and skip your own validation, assume:
– At least a few contracts are mis‑decoded.
– Some protocols migrated, and only part of the history is correctly labeled.
Always re‑run your own data quality layer, even on third‑party datasets.
—
Step 6. Entity Resolution: Addresses, Wallets, and Labels
Not every address is a “user”
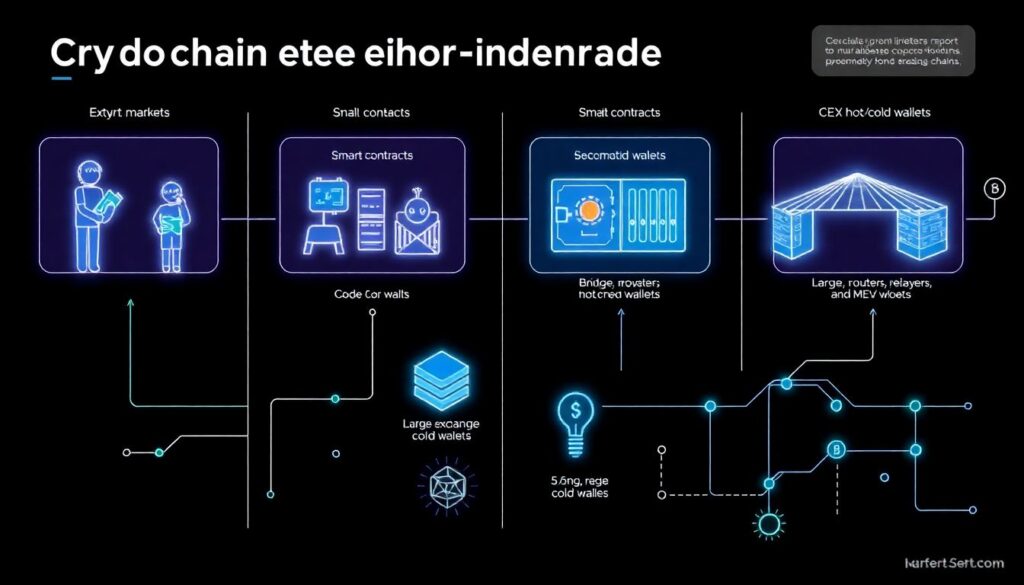
For any serious crypto market or on‑chain behavior study, you must separate:
– EOAs (externally owned accounts)
– Contracts
– Centralized exchange hot/cold wallets
– Bridges, routers, relayers, MEV bots
What to automate
– Heuristics for clustering
– Same entity using multiple addresses (e.g. CEX wallets, heavy arbitrage bots).
– On‑chain hints: common funding sources, shared withdrawal patterns, deterministic contract creation.
– Label consistency checks
– If an address labeled “CEX hot wallet” is suddenly interacting like a human wallet (NFT mints, random dApps), your labeling is wrong or outdated.
– Run periodic checks comparing current behavior with the historical cluster label.
– Cross‑chain resolution
– Use bridge events and chain‑specific tags to link entities across L1s and L2s.
– Validate that supposed cross‑chain entities show coherent timing and size patterns (e.g. same flow mirrored within minutes).
For beginners
Start with public label sources (exchange tags, big bridges), but don’t treat them as ground truth. Automate consistency checks that can revoke or downgrade a label from “certain” to “suspect”.
—
Step 7. Reconciliation Across Multiple Data Sources
“One dataset” is a single point of failure
If your research relies on only one API or data vendor, your results are hostage to their quirks. A robust setup reconciles multiple sources.
What to automate
– Price and volume reconciliation
– Pull the same pair from at least two vendors and your primary exchange source.
– Calculate differences over sliding windows.
– If deviations become structural (e.g. vendor A always 2% higher after a certain date), raise an alert and record a “bias” metric.
– On‑chain vs off‑chain consistency
– Compare CEX inflows/outflows inferred from labeled addresses with reported exchange data (where available).
– For stablecoins, reconcile on‑chain supply changes with issuer reports and oracle prices.
– Reference benchmarks
– Maintain your own internal benchmark series (e.g. VWAP across major exchanges).
– Whenever a data feed diverges sharply from the benchmark, quarantine that feed.
Common mistake
Using fancy crypto market data analytics software but forgetting to validate the inputs. Dashboards are only as good as the pipes feeding them.
—
Step 8. Automated Quality Scoring and Metadata
Not all data points are equal
Instead of a binary “clean/dirty” view of data, assign a quality score per row, candle, or event.
What to automate
For each record, compute:
– Completeness score (how many fields populated vs expected)
– Consistency score (passes internal schema / range checks)
– Source reliability score (based on provider history and reconciliation results)
– Transformation lineage (what cleansing steps were applied)
You don’t need a huge framework to start. A few integer flags such as:
– `is_backfilled`
– `is_outlier`
– `is_suspect_source`
– `passed_all_checks`
…already makes downstream analysis far safer.
Why it matters
When you train models, run event studies, or estimate risk, you can:
– Exclude low‑quality rows
– Re‑weight observations based on quality
– Run robustness checks (“results hold only on high‑quality slice?”)
—
Step 9. Putting It All Together With Tools and Platforms
Building vs buying in 2025
You don’t need to reinvent the wheel, but you also shouldn’t blindly trust plug‑and‑play products.
Today’s stack often mixes:
– In‑house scripts (Python, Rust, SQL)
– A general analytics warehouse (BigQuery, Snowflake, ClickHouse)
– A dedicated crypto trading data analysis platform for exploration and visualization
– Specialized crypto data quality tools or open‑source libraries for validation and monitoring
Key guidelines:
– Keep the core checks (schema, ranges, coverage) inside your own repo.
– Use vendors for scale, historical backfills and advanced indexing, but wrap all external inputs with your quality layer.
– Implement continuous monitoring, not just one‑off batch “cleansing”.
—
Step 10. Common Pitfalls and How to Avoid Them
Frequent errors
– Overfitting to one chain or market
– Checks calibrated for Ethereum often fail on Solana or L2s with different semantics.
– Automate chain‑specific rule sets.
– Ignoring latency and backfill bias
– Real‑time analytics vs historical replays see very different data (especially around liquidations and MEV).
– Always store: *when* data was first seen vs block time / trade time.
– Assuming “clean = truth”
– Aggressive filters can delete exactly the periods you study (e.g. crashes).
– Prefer labeling and scoring, not blind deletion.
Simple safety rules for beginners
– Never run a serious study on data you haven’t profiled. Automate a daily profile job (distributions, missingness, min/max).
– Tag every derived dataset with the commit hash of the code and versions of upstream sources.
– Treat your data pipeline as production software, not a throwaway script.
—
How to Start If You’re New (Minimal Viable Automation)
If all this feels like a lot, start small but systematic.
First wave (week 1–2)
Automate:
– Basic schema validation for each source
– Continuity checks on key time series (BTC, ETH, top 10 pairs you study)
– Simple price/volume sanity rules
Second wave (month 1–2)
Add:
– On‑chain ABI validation for a few core protocols
– Duplicate and gap handling with backfill logic
– Quality flags in your main tables
Third wave (month 3+)
Extend to:
– Cross‑source reconciliation
– Entity resolution labeling
– Quality scoring and monitoring dashboards
By this stage, you’ll naturally be using at least one crypto market data analytics software tool or custom dashboard with alerts tied to your data quality rules.
—
Looking Ahead: The Future of Automated Crypto Data Validation (2025–2030)
Where things stand in 2025
We’re now in a phase where:
– Data volumes exploded with L2s, rollups, app‑chains and high‑frequency perps.
– Institutional players demand auditable pipelines.
– Off‑chain and on‑chain signals are merging (CeFi, DeFi, RWAs, oracles).
As a result, automated crypto data validation is shifting from “nice to have scripts” to a core research competency — similar to unit tests in software engineering.
Likely developments over the next 5 years
1. End‑to‑end quality scores baked into vendors
– Major providers and crypto data quality tools will expose per‑row quality scores and provenance by default.
– Researchers will choose feeds not just on coverage and latency, but on verifiable quality metrics.
2. Standardization of crypto data contracts
– We’ll see widely adopted schemas and validation standards for trades, order books, DeFi events and cross‑chain transfers.
– Auditors and regulators will push for traceable data lineage in risk and compliance reports.
3. ML‑assisted anomaly and fraud detection at the data layer
– Models will flag suspicious patterns in both feeds and chains: spoofed volumes, wash trading, fake liquidity, manipulated oracles.
– These models will be integrated inside your data pipeline rather than bolted on at the analytics stage.
4. Tighter integration with blockchain data cleansing solutions
– Instead of one‑off ETL jobs, cleansing will be continuous, stateful and protocol‑aware (upgrades, forks, governance changes).
– Rollup validity/fraud proofs and light client infrastructure will be used directly to verify parts of your dataset.
5. Composable “research‑grade” stacks
– More researchers will combine:
– General cloud warehouses
– Domain‑specific pipelines for on‑chain indexing
– A flexible crypto trading data analysis platform for interactive work
– Quality checks will be shipped as open‑source modules you can plug into any stack.
What this means for individual researchers
If you learn to design and maintain robust data quality pipelines now, you’re future‑proofing your skillset.
In a few years, being “good with Python and SQL” but weak on data validation will look as outdated as running trading strategies in Excel.
The edge won’t just come from clever models — it will come from trustworthy data that others don’t have or don’t understand well enough.
—
Final Thoughts
Automating data quality checks isn’t an optional polish step; it’s the foundation of credible crypto research.
Start with:
– Schema and continuity checks
– Price/volume sanity rules
– Basic on‑chain and entity validation
Then gradually layer in more advanced reconciliation, scoring and monitoring. The tools will keep evolving — from bespoke scripts to integrated crypto data quality tools, from naive filters to ML‑driven anomaly detectors — but the core principle stays the same:
If you can’t defend your data, you can’t defend your conclusions.