

Why anomaly monitoring at scale hurts more than it should
If you track just a few wallets, “monitoring anomalies” feels easy: plug into an explorer, set alerts, done. At scale — hundreds of chains, millions of addresses, layered bridges, MEV bots — everything breaks. Latency creeps up, false positives explode, compliance teams drown in alerts they can’t triage. The gap between what a slick blockchain transaction monitoring software demo shows and what actually runs in production becomes painfully obvious. The real challenge in 2025 — and what we’ll unpack — is not “spotting weird transactions”, but building a system that stays accurate, explainable and cheap when the data firehose goes berserk.
Real-world cases: when anomalies become business‑critical
Let’s start with concrete stories. In 2023–2024 несколько крупных бирж столкнулись с атакой, где злоумышленники прогоняли средства через малоизвестные L2, а потом возвращали их обратно уже “чистыми” по текущим правилам. Старый on-chain analytics tool for crypto compliance смотрел только на мейннеты и крупные мосты, поэтому схемы отмывания не ловились неделями. Другой пример — NFT‑маркетплейс заметил резкий рост wash‑trading только после того, как маркетинговый бюджет уже был сожжен на “поддельный” объем. В обоих случаях сигналы были в данных раньше, но система не умела видеть аномалии в контексте всей сети и поведенческой истории контрагентов.
Основной стек: из чего вообще собирается мониторинг
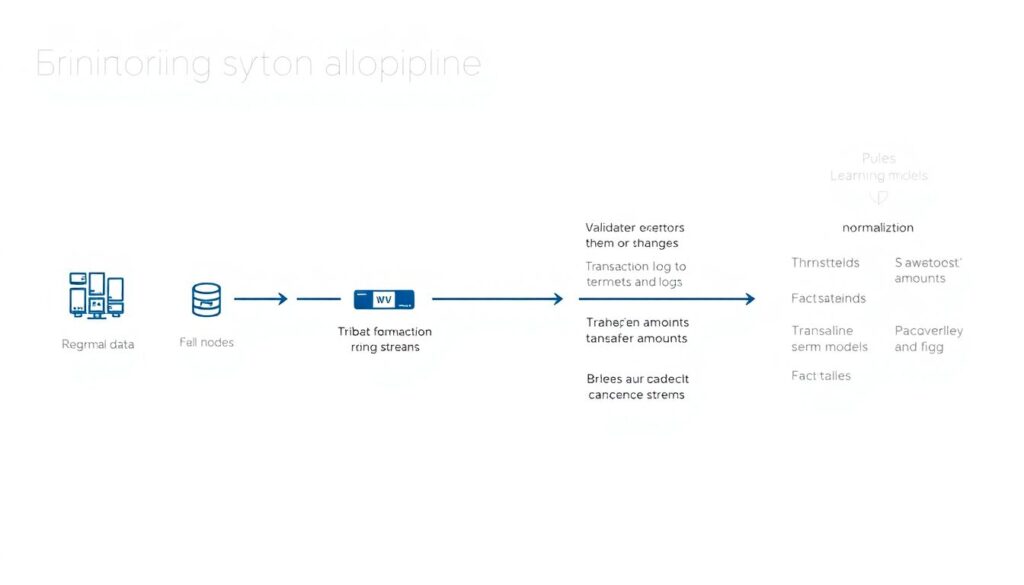
Любая система мониторинга начинаетcя с сырых данных: фулл‑нод, логов валидаторов, индексеров. Потом — нормализация: приводим разные форматы транзакций, событий и логов к единой схеме. Дальше появляются правила, эвристики и модели: лимиты по суммам, паттерны “пилообразных” переводов, а также ML, который понимает, что для этого конкретного смарт‑контракта нормально, а что похоже на атаку или обход санкций. Поверх всего — интерфейс и алертинг, где аналитик может отфильтровать шум. Звучит прямолинейно, но на больших объемах именно качественный пайплайн данных решает, а не красивая панель. Любой crypto AML transaction monitoring solution, который экономит на индексировании и дедупликации, рано или поздно тонет в хаосе.
Неочевидные источники сигналов: метаданные важнее сумм
Сумма перевода и список адресов — это только вершина айсберга. Гораздо ценнее то, что раньше игнорировали: временные паттерны, распределение газ‑прайсов, “почерк” кошелька в выборе маршрутов, повторяющиеся цепочки контрактов. Например, у одного DeFi‑протокола взломщик разделил атаку на сотни мелких операций в течение недели, чтобы не вылезти в стандартные лимиты. Их спасло то, что внутренняя real-time blockchain fraud detection platform заметила странное повторение маршрутов через малоиспользуемый роутер и одинаковое поведение ботов‑исполнителей. Вывод: чем больше связанных метаданных вы умеете собирать вокруг транзакции, тем меньше вам нужна грубая “магическая” модель сверху.
Аномалии не равны мошенничеству
Одна из главных ловушек — путать “статистическую странность” с реальной угрозой. В 2025 году объемы в DeFi скачут после каждого крупного релиза, ретродропа или запуска мем‑токена. Простая модель, которая кричит при любом резком росте активности, станет бесполезной уже через неделю. Гораздо полезнее учить систему разделять аномалии-поводы для исследования и аномалии-риски: первое — повод присмотреться к новым кластерам адресов или потенциальным инсайдерам, второе — прямое основание включить ограничение операций. Хорошее enterprise-scale blockchain analytics service как раз и зарабатывает тем, что умеет показать, почему конкретный алерт важен и как он связан с историей в цепочке, а не просто поднимает флаг “что-то странное”.
Альтернативные подходы: не только ML и не только правила

Часто обсуждение сводится к спору “правила против машинного обучения”. На практике лучшие команды комбинируют несколько подходов, причем не всегда очевидных. Помимо классических supervised‑моделей все чаще используют:
1. Графовый анализ для поиска аномальных подграфов и циклов вывода средств.
2. Байесовские модели, которые обновляют риск‑оценку адреса при каждом новом событии.
3. Легкие он‑чейн агенты, делающие предфильтрацию еще на уровне ноды.
4. Обратную симуляцию транзакций (dry‑run), чтобы понять реальные последствия до включения в блок.
Сильная сторона такой архитектуры — гибкость: правила можно менять ежедневно, не переписывая весь ML‑стек, а модели помогают там, где ручные эвристики уже не тянут из-за объема и сложности паттернов.
Неочевидные решения для снижения шума
Один из главных врагов — алерт‑фатига. Когда у команды сотни уведомлений в час, люди начинают игнорировать даже важные сигналы. Чтобы этого избежать, продвинутые команды внедряют ранжирование алертов и контекстное объединение: серия из 50 мелких переводов от одного кластера адресов попадает в интерфейс как один кейс, а не 50 отдельных задач. Еще одна хитрость — обучение на “отклоненных” алертах: если аналитики стабильно помечают определенный тип событий как несущественный, система постепенно занижает их приоритет. Такой подход превращает статичный on-chain analytics tool for crypto compliance в живой инструмент, который подстраивается под реальные рабочие процессы, а не под презентацию для инвесторов.
Лайфхаки для профессионалов: как не утонуть в продакшене
Командам, которые уже выбрали или строят собственный стек, полезно держать в голове несколько практических правил:
1. Сначала качество данных, потом сложные модели. Устраните дубли, сортируйте события, проверяйте консистентность индексов.
2. Стройте “обратную совместимость”: новые правила не должны ломать старую аналитику и отчеты.
3. Заложите бюджет на параллельный мониторинг нескольких поставщиков данных — cross‑check часто вылавливает критические расхождения.
4. Разделите “оповещение” и “блокировку”: автоматический стоп операции — крайняя мера, используйте ее только при действительно жестких сигналах.
5. Логируйте все решения: через полгода будет важно понять, почему та или иная транзакция была пропущена или, наоборот, остановлена.
Что выбирать: готовое решение или свой стек
В 2025 году рынок решений раздулся: от простых дешевых дашбордов до полноценных managed‑платформ. Готовый crypto AML transaction monitoring solution ускоряет старт, но почти всегда встает вопрос кастомизации под ваше риск‑аппетит и локальное регулирование. Собственный стек дает гибкость, но требует людей, которые понимают и блокчейн‑инфраструктуру, и модели, и требования регуляторов. Компромиссный вариант — использовать готовый real-time blockchain fraud detection platform как базовый слой, а поверх него строить свои правила, обогащенные внутренними данными: KYC, поведение пользователей в продукте, историю тикетов в саппорте. Важно не застрять в ситуации, когда смена одного вендора превращается в годовой проект миграции.
Масштабирование: технические и организационные грабли
Когда система растет от одной сети к десяткам, неожиданно выясняется, что главные проблемы не в алгоритмах. Одни протоколы активно форкаются, и вы внезапно получаете десятки похожих контрактов с тонкими отличиями; другие меняют формат логов так, что старый парсер тихо ломается. Отсюда первый принцип масштабирования — изначально проектировать конвейер как модульный: новый чейн добавляется как “плагин”, с четкими контрактами данных. Второй — разделение команд: те, кто пилит ядро системы, не должны параллельно гоняться за каждым новым токеном‑скамом. И третье — план по деградации: что будет, если часть индексеров ляжет, а объем транзакций внезапно удвоится из‑за хайпа?
Прогноз до 2030: куда движется мониторинг аномалий
На горизонте пяти лет мониторинг станет гораздо более “прозрачным” и совместимым. Регуляторы уже требуют стандартизированных форматов отчетности для on-chain рисков, а значит, enterprise-scale blockchain analytics service будут вынуждены поддерживать общие словари рисков и объяснимые модели. Параллельно развивается идея “самомониторинга”: протоколы встраивают в себя механизмы авто‑паузы при подозрительных паттернах, а валидаторы и секвенсоры получают экономические стимулы отбрасывать явные атаки еще до включения в блок. Наконец, появится больше публичных, полу‑децентрализованных сетей сигналов о рисках, где события с высокой степенью уверенности будут помечаться на уровне всей экосистемы, а не внутри каждого сервиса по отдельности. Тем, кто уже сейчас закладывает открытые стандарты и хорошо документированный API, будет легче встроиться в этот мир.