
Why anomaly‑based alerts matter in crypto monitoring
Anomaly‑based alerts are basically your “something feels off” sense, but automated. Instead of hard‑coding rules like “alert if transfer > 10 BTC,” you teach your system what *normal* looks like, then flag anything that strays too far from that baseline.
In the crypto world, where attackers constantly change tactics, this approach gives you a fighting chance to catch new patterns of abuse, not just the ones you already know about.
If you’re using any serious crypto transaction monitoring software today, anomaly detection is either already inside it or can be integrated around it. The trick is to set it up in a way that catches real threats without drowning your team in noise.
—
Step 0: Get your foundations in order
Know what you’re actually monitoring
Before writing a single line of code or turning on machine‑learning features, define your scope:
– Which chains and assets are in scope? (Bitcoin, Ethereum, stablecoins, niche L2s?)
– Are you watching on‑chain only, or also internal ledger movements?
– Are you focused on retail users, institutional flows, or both?
Without this, your anomaly engine will end up half‑blind or overly sensitive.
Pick the right tools, not just the shiny ones
You don’t need an exotic tech stack to start, but you do need components that talk to each other cleanly.
At minimum, you’ll want:
– Data ingestion
– Node RPCs, indexers, or data providers (e.g., for historical and mempool data)
– Streaming layer (Kafka, Kinesis, Pub/Sub, or a managed pipeline)
– Storage and features
– A database or data lake for historical transactions
– Feature store or at least a structured way to keep engineered features (balances, velocity, counterparties, etc.)
– Analytics and detection
– A blockchain analytics tool for AML compliance, ideally one that enriches addresses with risk scores, labels, and clustering
– A machine‑learning library or anomaly detection framework (e.g., scikit‑learn, PyTorch, or managed ML services)
– Optionally, a real-time crypto anomaly detection platform if you don’t want to build everything yourself
– Alerting and workflow
– Integration with your case management system or ticketing tool
– Notification channels (email, Slack, PagerDuty, etc.)
If you’re short on engineering resources, consider crypto compliance monitoring as a service providers. They usually give you APIs for risk scores and anomaly flags so you can focus on policies and investigations instead of infrastructure.
—
Designing your anomaly strategy (before touching the keyboard)
Define “normal” for your context
“Normal” is not universal. A big exchange, a DeFi protocol, and an OTC desk all have wildly different traffic patterns.
Start by segmenting users or entities into roughly comparable groups:
– Retail users vs. high‑net‑worth vs. institutional
– New accounts vs. seasoned accounts
– Low‑risk geographies vs. high‑risk ones
– On‑ramp / off‑ramp users vs. pure on‑chain traders
Within each segment, inspect historical data and ask:
– What’s the usual transaction size and volume per day?
– How often do they interact with high‑risk addresses?
– What’s the typical time‑of‑day activity pattern?
– How often do they change deposit/withdrawal addresses?
Your anomaly models will perform much better on these homogeneous segments than on one giant mixed pool of behavior.
Choose which anomalies you care about
You can’t detect everything at once. Focus early on patterns that map clearly to risk:
– Sudden spikes in volume or frequency
– Unusual counterparties (brand‑new wallets, risky clusters)
– Rapid changes in behavioral patterns (time zones, assets, chains)
– Structuring behavior (many small transfers replacing a few large ones)
– Abnormal interactions with mixers, sanctioned entities, or darknet‑linked wallets
An effective cryptocurrency fraud detection solution usually combines statistical oddities with contextual signals: address risk, KYC data, IP/geolocation, device fingerprints, and so on.
—
Step‑by‑step: Implementing anomaly‑based alerts
Step 1: Build a clean, enriched data pipeline
This is where many teams cut corners and pay for it later.
1. Ingest raw blockchain data
Pull transactions, logs, and traces from your nodes or a data provider. Include:
– Sender, receiver, hashes
– Amounts and asset types
– Block time and confirmations
– Gas/fees and contract interactions
2. Enrich with external intelligence
Connect your blockchain analytics tool for AML compliance to:
– Label known entities (exchanges, mixers, DeFi protocols)
– Attach risk indicators (sanctions exposure, darknet links, scams)
– Group related addresses into clusters when possible
3. Join with internal and KYC data
Tie on‑chain addresses to:
– User accounts and KYC profiles
– Device IDs, IP ranges, and login metadata
– Historical balances and previous flags
If the underlying data is messy, your anomalies will be misleading. Duplicate records, missing timestamps, or inconsistent address mapping are classic sources of false positives.
Step 2: Engineer behavioral features
Raw transactions aren’t ideal for anomaly detection. You need to transform them into meaningful behavioral metrics.
Examples of helpful features:
– Volume / velocity
– Total volume sent/received over sliding windows (1h, 24h, 7d)
– Count of transactions per window
– Ratio of on‑chain volume to internal ledger movements
– Counterparty structure
– Number of unique counterparties in the last N days
– Fraction of volume going to high‑risk or unlabeled entities
– Recurrence of counterparties (first time vs. repeat interactions)
– Temporal behavior
– Usual active time windows (e.g., local daytime vs. sudden activity at 3am)
– Burstiness: quiet for days, then huge spikes
– Diversity of assets and chains
– Number of different tokens and networks used
– Sudden switch from a “stablecoins only” pattern to speculative tokens
Aggregate these features per entity: per user, address cluster, or account, depending on your model. Store historical snapshots so your anomaly logic can compare “today vs. last week/month.”
Step 3: Pick and configure anomaly detection methods
You don’t have to jump straight into deep learning. Start with simpler methods that are transparent and easy to debug.
Common approaches:
– Rule‑supported statistics
– Z‑scores or percentile thresholds per segment
– Time‑series deviation from moving averages
– Conditional thresholds (e.g., “>3x usual daily volume *and* >$10k”)
– Unsupervised ML
– Isolation Forest, One‑Class SVM, or Local Outlier Factor on feature vectors
– Clustering (e.g., DBSCAN) to find users whose behavior doesn’t fit any group
– Hybrid approaches
– Rules for hard regulatory constraints (e.g., sanctions exposure)
– Unsupervised models to surface weird but not yet known attack patterns
Early on, focus on interpretability. Investigators must be able to look at an alert and understand *why* it was flagged.
Step 4: Calibrate thresholds and scoring
This step is about balancing sensitivity and noise.
– Use historical data to simulate how many alerts each configuration would generate.
– Start with more conservative thresholds; then gradually tighten them.
– Implement a risk score, not just binary alerts. For example:
– Base anomaly score from the model
– Plus points for exposure to known high‑risk entities
– Plus points for interacting from new device/IP
– Minus points for long account tenure and clean history
Review the top N alerts per day with your analysts and adjust:
– Which alerts were actually useful?
– Which were obviously benign and why?
– Is there a repeating false positive pattern you can codify away?
—
Step 5: Integrate alerts into your workflows
Make alerts actionable, not just noisy messages
An alert should give an investigator enough context to take a first decision without fishing around.
Include, at minimum:
– Brief description of why it fired (“3x daily volume, new counterparties in high‑risk country, large mixer exposure”)
– Key metrics (amount, time window, risk scores)
– Historical baseline for comparison
– Fast links to underlying transactions, user profile, and previous alerts
Tie this into your case management or ticketing system so that each anomaly can be triaged:
– Auto‑close low‑risk anomalies with clear explanations
– Escalate medium‑risk ones for human check
– Auto‑freeze or hold withdrawals only for the highest‑risk cases where your policy allows it
If you’re using a real-time crypto anomaly detection platform, most of this workflow may already exist; your job becomes configuring routing, severity, and suppression rules.
—
Common beginner mistakes (and how to avoid them)
Mistake 1: Turning on “AI” and expecting magic
A lot of teams enable an anomaly module in their crypto transaction monitoring software, leave default settings, and then hope it will “find the bad guys.”
What goes wrong:
– The model is trained on generic data, not your user base.
– Thresholds aren’t tuned for your risk appetite.
– Analysts get flooded with meaningless alerts and start ignoring them.
Fix: Treat anomaly detection as a project, not a switch. Customize segments, tune thresholds from historicals, and run in “shadow mode” (no real actions) for a few weeks to see what it actually surfaces.
Mistake 2: Ignoring data quality
New teams often over‑index on algorithms and under‑index on clean data.
Typical issues:
– Inconsistent user–address mapping (one user looks like ten)
– Missing timestamps or wrong time zones
– Duplicated or partially ingested blocks
These quietly destroy your “normal behavior” baselines.
Fix:
Invest early in validation checks:
– Daily counts comparison with chain explorers
– Schemas with required fields and constraints
– Automated alerts when ingestion lags or drops
Mistake 3: No feedback loop from investigators
Analysts spend their day looking at these alerts, but their feedback never reaches the model owners.
Result:
– Same false positives repeat for months.
– True positives don’t inform better detection logic.
– People lose trust in the system.
Fix:
Add a simple feedback mechanism:
– Each alert can be tagged as:
– “True positive – confirmed suspicious”
– “False positive – benign known pattern”
– “Inconclusive – monitored only”
– Periodically (weekly or monthly) review tags and update:
– Rules to suppress recurrent benign patterns
– Features or weights that predict confirmed cases better
Mistake 4: Over‑aggressive blocking based on first anomalies
Newcomers sometimes auto‑freeze accounts on the very first anomaly, especially after adopting a shiny new cryptocurrency fraud detection solution. That might feel “safe,” but it can cause serious user friction and even regulatory questions if you apply it inconsistently.
Fix:
Design graduated responses:
– First‑time, low‑severity anomalies → silent monitoring or soft friction (extra verification)
– Repeated or severe anomalies → manual review with possible temporary limits
– Only the clearest, highest‑risk scenarios → automated hard blocks, backed by policy
Mistake 5: One giant model for everyone
A single global model that treats a small retail user the same as a market‑maker is doomed. You’ll miss subtle abuse in low‑volume segments and over‑flag whales whose behavior is inherently spiky.
Fix:
Segment first, then model. Each segment gets its own baselines and thresholds. In some segments, simple rules and statistics may outperform more complex ML approaches.
—
Troubleshooting: When your anomaly alerts misbehave
Problem: Too many false positives
If your analysts are drowning:
– Check features for drift
– Did your user base change? (e.g., new region, new product)
– Did you add a new chain or asset that skews volumes?
– Tighten your trigger logic
– Replace “> 3x baseline” with “> 3x baseline *and* above an absolute floor (e.g., $2,000)”
– Suppress alerts for long‑tenure users with clean history unless risk exposures are high
– Whitelist predictable spikes
– Product launches, marketing campaigns, airdrops, and seasonal events all create noisy anomalies. Pre‑tag them and reduce their weight in scoring.
Problem: You’re missing obvious bad behavior
If post‑mortems show that major incidents weren’t flagged:
– Revisit which features you’re using
– Are you considering counterparties, or just user‑side behavior?
– Did you factor in exposure to high‑risk clusters from your AML tools?
– Incorporate supervised elements
– Take known bad cases and analyze how their features differ.
– Turn those patterns into explicit rules or higher model weights.
– Adjust time windows
– Some schemes evolve over weeks, not hours. Add 7d/30d windows alongside short‑term ones.
Problem: Alerts are delayed or inconsistent
When alerts fire late or unpredictably:
– Confirm your data pipeline latency
– Are you receiving blocks in near real time?
– Is enrichment (e.g., address labeling) happening synchronously or with lag?
– Monitor model execution time
– For heavy models, move some logic to batch processing and keep real‑time checks lightweight.
– Cache frequently used features so you’re not recomputing for every transaction.
– Harden error handling
– On failures, don’t silently drop events. Log, retry, and emit internal alerts for pipeline issues.
—
Putting it all together
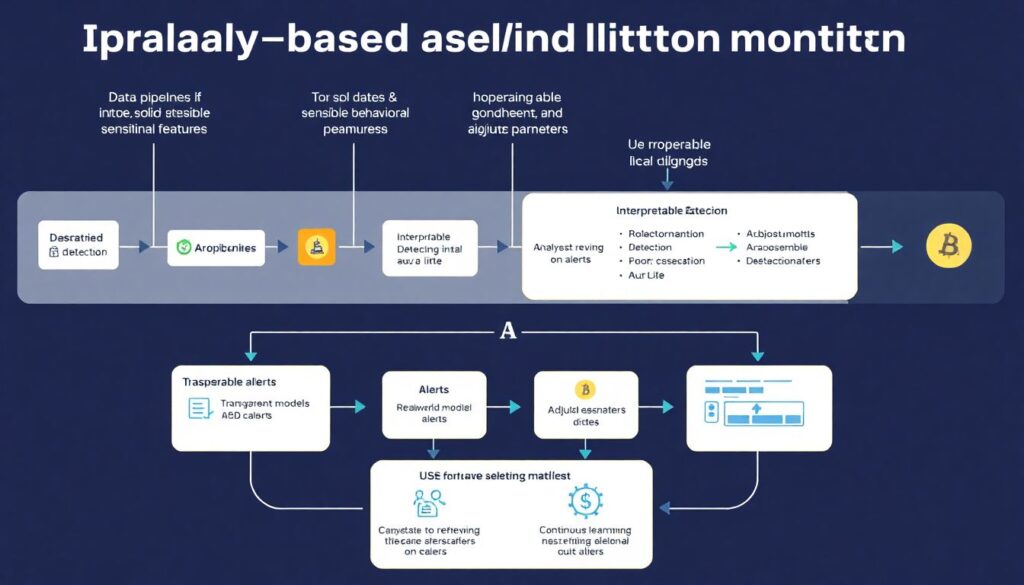
Implementing anomaly‑based alerts in crypto monitoring isn’t about plugging in a fancy library and walking away. It’s about:
– Getting solid data and sensible behavioral features
– Choosing detection methods you can explain and tune
– Integrating alerts into real‑world workflows
– Constantly learning from both true and false positives
Whether you build everything in‑house or lean on providers offering crypto compliance monitoring as a service, the principles stay the same: define normal clearly, focus on high‑impact anomalies, avoid panicking your users with over‑reactive blocks, and keep iterating. If you respect those basics, your anomaly‑based system will gradually evolve from a noisy gadget into a core part of your risk defense.