
Гайд по настройке слежения за новостями через графовые запросы
В эпоху информационного изобилия традиционные методы мониторинга новостей теряют эффективность. Огромные потоки данных требуют более интеллектуального подхода — именно здесь на сцену выходят графовые запросы. Этот метод позволяет не просто собирать новости, а выявлять взаимосвязи между источниками, событиями, лицами и темами. В данной статье мы пошагово разберём, как настроить систему слежения за новостями с использованием графовых запросов, а также поделимся статистикой и практическими советами.
Что такое графовые запросы и как они применяются в новостном мониторинге
Графовые запросы — это способ извлечения информации из графовых баз данных, в которых данные представлены в виде узлов (entities) и рёбер (relationships). Такие базы, как Neo4j, Amazon Neptune или ArangoDB, позволяют эффективно анализировать связи между объектами.
В контексте новостей это означает возможность:
– Отслеживать, как часто упоминается конкретное лицо в контексте определённого события;
– Выявлять связи между компаниями, политиками и событиями;
– Строить временные цепочки упоминаний и их взаимосвязей.
Зачем это нужно
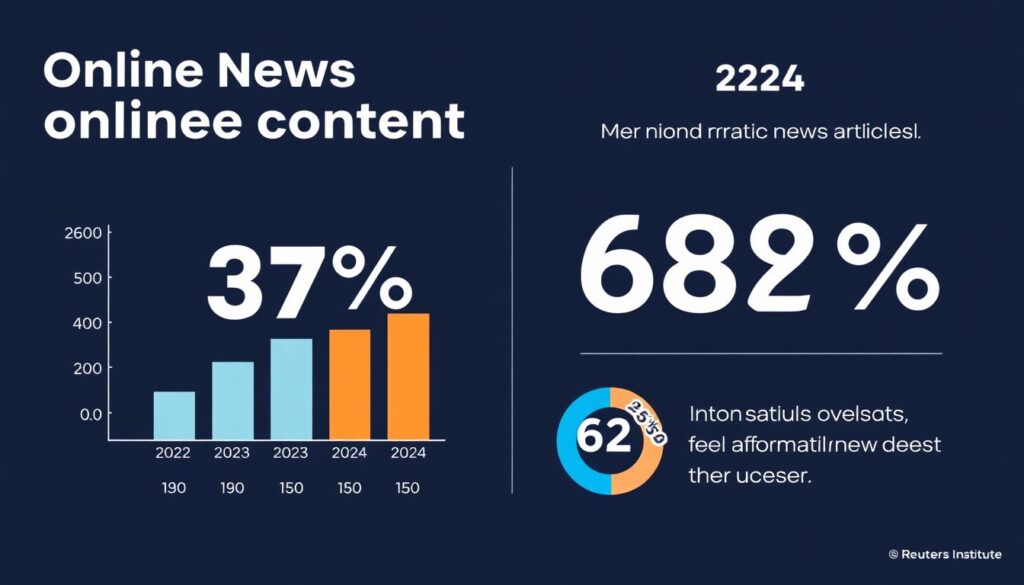
По данным Statista, объём новостного контента в интернете увеличился на 37% с 2022 по 2024 год. Только в 2024 году было опубликовано более 1,2 миллиарда новостных статей по всему миру. При этом, по оценке Reuters Institute, 68% пользователей испытывают информационную перегрузку.
Графовые запросы позволяют не просто фильтровать новости, а выстраивать смысловые связи, что делает анализ более глубоким и контекстуальным.
Пошаговая настройка системы слежения за новостями
Шаг 1: Сбор данных
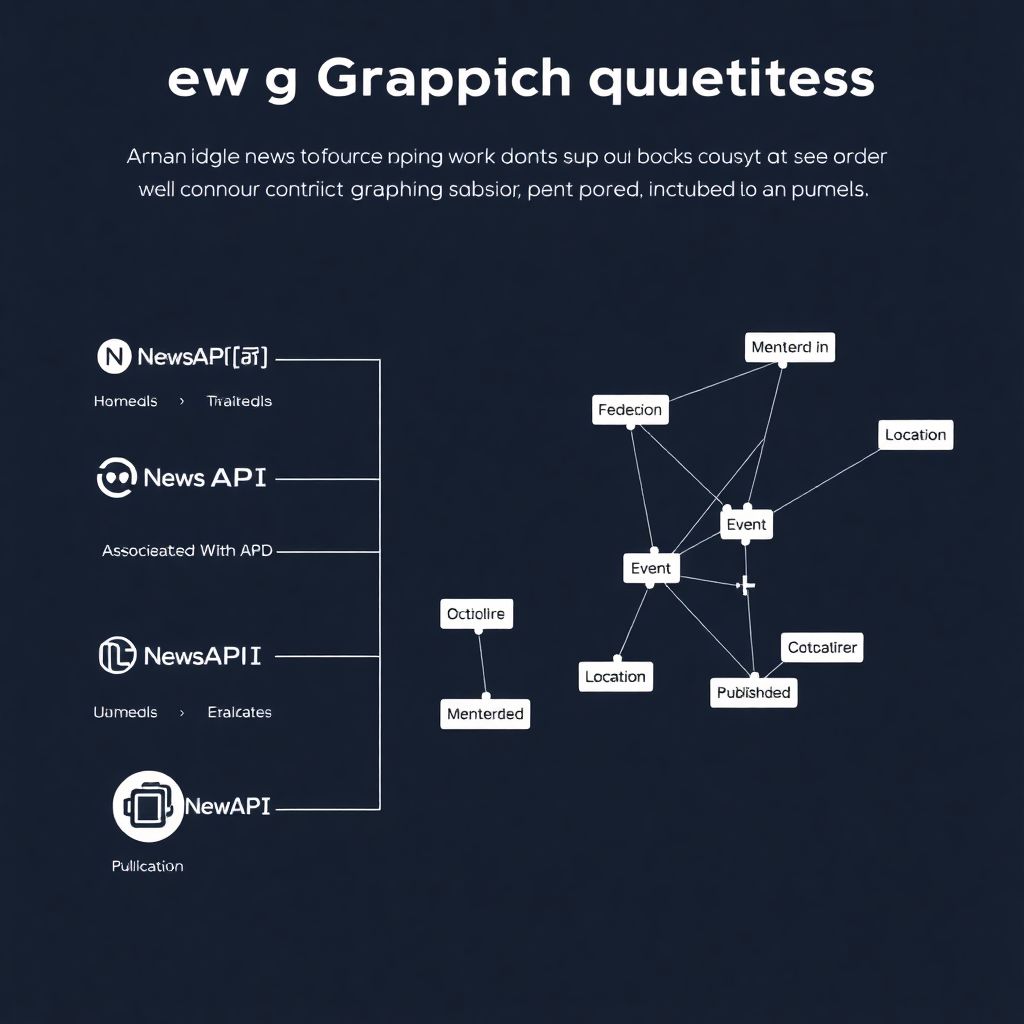
Первый этап — получение новостных данных. Используйте API новостных агрегаторов, таких как:
– NewsAPI.org
– GDELT Project
– EventRegistry
– Media Cloud
Важно: убедитесь, что выбранный источник предоставляет метаданные (время публикации, автор, категория), так как они критичны для построения графа.
Совет: для лучших результатов комбинируйте несколько источников, чтобы минимизировать искажения и перекосы.
Шаг 2: Предобработка информации

До загрузки в графовую базу необходимо:
1. Очистить текст от HTML, спецсимволов, рекламы.
2. Провести Named Entity Recognition (NER) — выделение сущностей (люди, организации, места).
3. Установить связи между сущностями (например, «Илон Маск» — «связан с» — «SpaceX»).
Для этого подойдут библиотеки:
– spaCy (Python)
– Stanford NLP
– DeepPavlov (для русского языка)
Предупреждение: некачественная NER-аннотация приведёт к неверным связям в графе. Проверьте точность моделей на выборке вручную.
Шаг 3: Создание графовой модели
В графовой базе создаются типы узлов:
– Person (человек)
– Organization (организация)
– Event (событие)
– Location (место)
– Article (статья)
И типы рёбер:
– MENTIONED_IN
– ASSOCIATED_WITH
– LOCATED_AT
– PUBLISHED_ON
Пример запроса (на языке Cypher для Neo4j):
“`cypher
MATCH (p:Person)-[:MENTIONED_IN]->(a:Article)
WHERE a.date > date(‘2024-01-01’)
RETURN p.name, count(a) AS mentions
ORDER BY mentions DESC
“`
Этот запрос покажет, кто чаще всего упоминался в новостях с начала 2024 года.
Шаг 4: Настройка графовых запросов для мониторинга
Теперь вы можете строить запросы для:
1. Отслеживания тематики (например, «искусственный интеллект» и его упоминания в политическом контексте).
2. Детектирования всплесков активности (например, резкое увеличение упоминаний компании).
3. Поиска скрытых связей (например, общие события между двумя организациями).
Совет: автоматизируйте выполнение запросов раз в сутки и сохраняйте результаты в аналитическую базу (например, PostgreSQL или ClickHouse).
Ошибки, которых стоит избегать
1. Игнорирование временного контекста
Графы без временных меток теряют свою аналитическую ценность. Всегда сохраняйте дату публикации и учитывайте её в запросах.
2. Перегрузка графа нерелевантными сущностями
Не стоит добавлять в граф все упомянутые слова. Ограничьтесь ключевыми сущностями, иначе граф станет шумным и труднообрабатываемым.
3. Отсутствие нормализации
«Apple Inc.» и «Apple» — это одна и та же сущность. Используйте словари синонимов или внешние базы (например, Wikidata) для нормализации.
Советы для новичков
– Начинайте с небольшого количества источников и сущностей. Постепенно расширяйте граф.
– Используйте визуализацию (Neo4j Bloom, Graphistry) для проверки связей.
– Не гонитесь за полным охватом — лучше меньше данных, но высокой точности.
– Читайте документацию к графовым СУБД — язык запросов может отличаться.
– Автоматизируйте рутинные задачи с помощью Airflow или cron-скриптов.
Тренды и статистика 2022–2024 гг.
– По данным GDELT, в 2024 году количество уникальных событий, зафиксированных в новостях, превысило 500 миллионов — рост на 42% по сравнению с 2022.
– Использование графовых баз данных в медиа-аналитике выросло на 61% в период с 2022 по 2024 год (данные DB-Engines).
– В 2023 году 34% крупных медиакомпаний начали внедрение графовых систем для анализа новостей (по отчёту Gartner).
– Количество упоминаний тем, связанных с ИИ, в 2024 году выросло на 78% по сравнению с 2022 (по данным Media Cloud).
Заключение
Графовые запросы — мощный инструмент для интеллектуального анализа новостей. Они позволяют не просто следить за публикациями, но и выстраивать смысловые карты событий и связей между участниками. Такой подход особенно полезен в аналитике, журналистике, PR и конкурентной разведке.
Систематический и аккуратный подход к построению графа, настройке запросов и интерпретации результатов — ключ к получению ценной информации в условиях информационного шума. Начните с малого, автоматизируйте процессы и постепенно расширяйте охват — и вы получите инструмент, который будет работать на вас 24/7.