
Basics of cross-chain transaction latency
Key definitions
When people argue about “fast bridges”, они на самом деле говорят о latency, но часто без чётких терминов. Под cross-chain transaction latency будем понимать время от момента, когда пользователь инициирует действие на исходной сети, до момента, когда средства или сообщение становятся необратимо доступными в целевой сети. Это не только скорость подписи блоков, но и задержки очередей, проверок доказательств и подтверждений валидаторов. Для корректного blockchain transaction latency measurement нужно отдельно фиксировать пользовательский опыт (UX‑латентность) и техническую финализацию на уровне протокола.
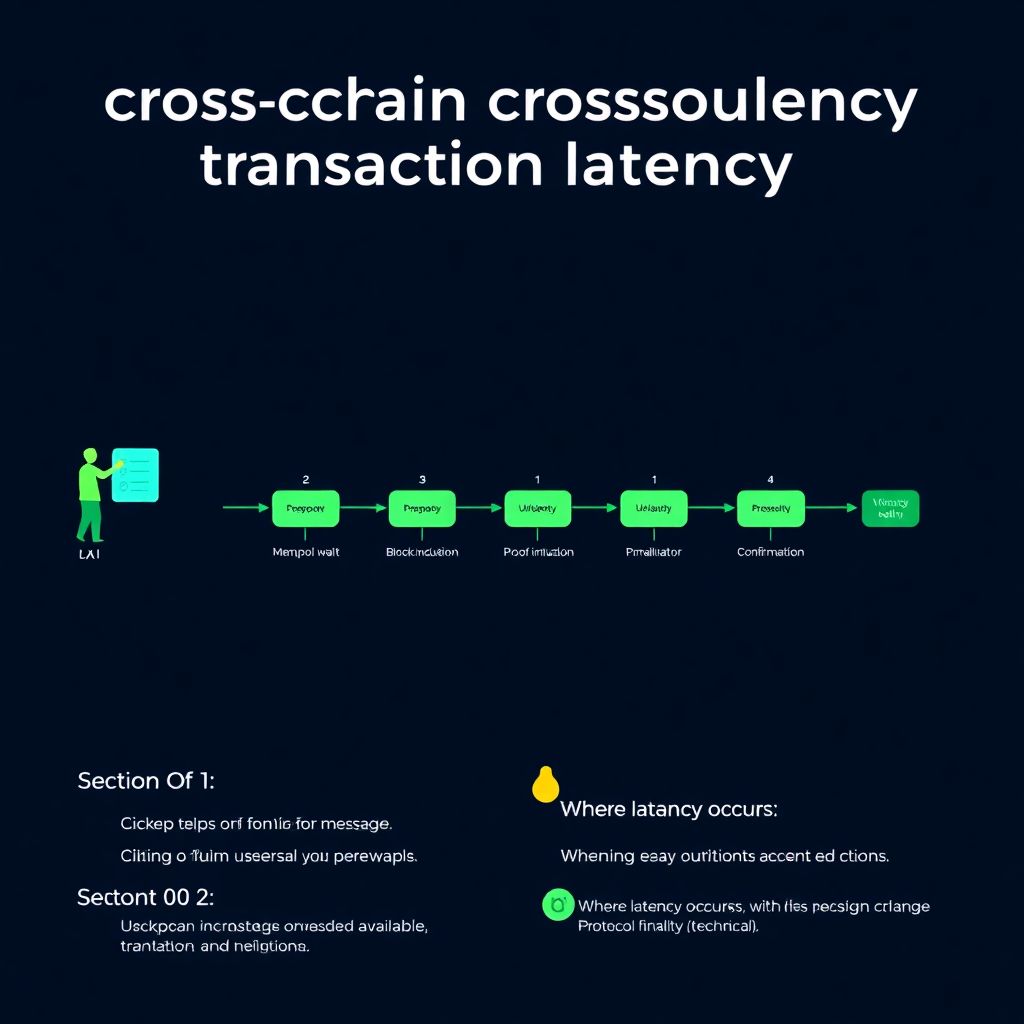
Где именно возникает задержка
Упрощённо мост можно разложить на несколько этапов, каждый добавляет свою долю задержки. Сначала транзакция попадает в мемпул исходной сети, потом включается в блок, далее оффчейн‑релеи или валидаторы мостов агрегируют события, формируют доказательства и публикуют их в целевой сети. Там происходит верификация, очередной блокмайнинг и, наконец, выпуск токенов или разблокировка нативных активов. На каждом шаге своя статистика: от загрузки сети и пропускной способности до настроек безопасности самого протокола.
—
Measurement models and time points
Что именно мы измеряем?
Если просто замерять время “от клика в интерфейсе до поступления средств”, получится удобная метрика для пользователя, но мало пригодная для инженерного анализа. Разработчикам важно разбивать общую задержку на компоненты: время ожидания в мемпуле, время включения в блок, скорость генерации доказательства, задержки сети между нодами, финализацию в целевой сети. Поэтому грамотная схема измерения всегда основана на нескольких опорных точках времени и чёткой модели событий, а не на единственном таймстампе из фронтенда.
Текстовые диаграммы потока
Полезно мыслить в виде простых ASCII‑диаграмм. Например, детальный поток для lock‑and‑mint моста:
`User -> L1_Tx_Submit -> L1_Block_Inclusion -> Bridge_Listener -> Proof_Builder -> L2_Tx_Submit -> L2_Block_Inclusion -> L2_Finality`
Для каждой стрелки мы можем считать свою дельту времени. Вторая схема для message‑passing моста (например, L2 → L1):
`App_Contract -> Outbox_Enqueue -> L2_Finality -> Prover -> L1_Inbox_Tx -> L1_Block_Inclusion -> L1_Safe_Execution`
Такие диаграммы помогают однозначно обсуждать, какая именно часть цепочки сейчас “тормозит” и где стоит добавлять метрики.
—
Instrumentation and tools
Методы на основе ончейн‑таймстампов
Самый доступный способ — измерять разницу между временными метками блоков, в которых появились исходное и целевое события. Мы фиксируем номер и timestamp блока с исходной транзакцией и аналогичные данные для транзакции в целевой сети, а затем вычисляем дельту. Такой подход удобен для бэкенд‑сервисов и легко автоматизируется: достаточно RPC‑нод и индексирующего слоя. Минус — точность ограничена частотой блоков и особенностями консенсуса, а также отсутствием учёта задержек на уровне фронтенда и кошелька пользователя.
Оффчейн‑пробы и синтетические тесты
Чтобы увидеть “реальное” время глазами пользователя, полезно запускать синтетические прогоны: регулярные тестовые переводы между сетями, отправляемые скриптом через тот же кошелёк, что и у живых пользователей. Скрипт записывает время клика, время появления транзакции в мемпуле (по RPC), момент включения в блок и финализацию на принимающей сети. Такие synthetic probes компенсируют слепые зоны ончейн‑методик и позволяют учитывать сетевые задержки RPC‑провайдеров, производительность фронтенда, а также поведение кошельков и подписи.
—
Using monitoring platforms
Метрики в blockchain performance monitoring tools
Современные blockchain performance monitoring tools умеют собирать огромный объём сигналов: от времени ответа RPC до глубины мемпула и скорости финализации. Для измерения cross‑chain latency особенно полезны: распределение задержки между этапами, перцентильные метрики (P50/P95/P99), частота таймаутов и неуспешных попыток. Важно интегрировать мониторинг именно на уровне бизнес‑событий моста, а не только сырых транзакций. Это позволяет увязать показатели с конкретными маршрутами и активами, а не размывать картину по всей сети.
Роль cross-chain bridge analytics platform
Когда мостов и сетей становится много, ручного сбора статистики уже не хватает, и нужен специализированный cross-chain bridge analytics platform. Такие системы агрегируют логи разных нод, события смарт‑контрактов и метрики инфраструктуры, строят связи между исходными и целевыми транзакциями и автоматически считают latency для каждой пары сетей. Дополнительно они помогают визуализировать “бутылочные горлышки” и аномалии: внезапный рост задержки на конкретном маршруте, деградацию определённого релейера или влияние обновления протокола на общую пропускную способность мостов.
—
Monitoring cross-chain flows in practice
Cross-chain transaction monitoring software
Выстраивая практический стек, команды часто комбинируют готовое cross-chain transaction monitoring software с собственными скриптами. Типичная схема выглядит так: внешняя платформа отвечает за сбор ончейн‑данных, построение временных рядов и алёртов, а кастомный код — за разметку бизнес‑событий и мэппинг “source tx → target tx”. Такой подход снижает порог входа и при этом оставляет пространство для тонкой настройки под особенности конкретного моста, будь то ликвидити‑пулы, нативные бриджи или message‑passing решения между L1 и L2.
web3 infrastructure performance monitoring
Если latency прыгает без видимых причин, виновата не всегда логика контракта. Часто проблема скрывается в RPC‑слое, сети валидаторов или конфигурации нод, поэтому web3 infrastructure performance monitoring обязателен. Эксперты рекомендуют отслеживать:
– время ответа RPC и частоту ошибок по регионам;
– загрузку нод (CPU, диск, очередь запросов);
– задержку распространения блоков между пирами.
Связав эти данные с метриками моста, можно отделить проблемы протокола от сбоев инфраструктуры и точнее планировать оптимизации.
—
Expert recommendations and best practices
Designing a measurement strategy
Опытные инженеры по наблюдаемости советуют начинать не с инструментов, а с чёткой схемы событий. Сначала вы рисуете детальную диаграмму пути транзакции через мост и определяете ключевые точки времени, затем уже размечаете их логами, метриками и ончейн‑событиями. Полезно в явном виде сформулировать SLA по latency для разных маршрутов и активов, а потом строить систему измерений именно под эти цели. Тогда blockchain transaction latency measurement перестаёт быть хаотичной сводкой цифр и превращается в управляемый инженерный процесс.
Сравнение между мостами и сетями
Для честного сравнения разных мостов и L1/L2‑комбинаций эксперты советуют использовать унифицированные сценарии и одинаковые synthetic probes. В каждом сценарии фиксируйте: размер перевода, тип актива, время суток, тип кошелька и маршрут. Полезно собирать не только среднее время, но и хвосты распределения, а также долю транзакций, превысивших заданный порог. На этой базе можно строить рейтинги по latency и уже осознанно выбирать решения для своего продукта, а не руководствоваться маркетинговыми заявлениями о “моментальных переводах”.