
Необходимые инструменты для построения моделей на основе on-chain данных
Для создания эффективной модели ценообразования на основе on-chain данных потребуется ряд специализированных инструментов и платформ. В первую очередь стоит обратить внимание на системы индексирования блокчейна, такие как The Graph или Dune Analytics, которые позволяют быстро и удобно извлекать структурированные данные. Для сбора и хранения информации можно использовать базы данных с поддержкой больших объемов, например PostgreSQL или BigQuery. Аналитика и построение моделей — область Python с библиотеками Pandas, Scikit-learn и PyMC3 для байесовского моделирования. Также важно наладить доступ к API блокчейнов (например, Etherscan, Alchemy или Infura) для оперативного получения последних данных.
Пошаговый процесс построения модели ценообразования
Построение модели следует организовать в логической последовательности, где каждый этап формирует основу для следующего:
1. Определение цели модели — определите, что именно должна предсказывать модель: краткосрочную цену, долгосрочную справедливую стоимость или уровень переоценённости.
2. Сбор on-chain данных — извлеките метрики вроде объема транзакций, количества активных адресов, средней комиссии, скорости прироста токенов и прочих показателей.
3. Предобработка — очистите данные от аномалий, примените нормализацию, логарифмирование или сглаживание, чтобы устранить шум.
4. Инженерия признаков — создайте составные индикаторы: например, соотношение между количеством новых адресов и удержанием токенов, или индекс концентрации холдеров.
5. Обучение модели — примените машинное обучение (градиентный бустинг, рекуррентные нейросети или байесовские методы) для обучения на исторических данных.
6. Оценка результатов — используйте метрики вроде MAE, RMSE и R², а также кросс-валидацию, чтобы убедиться в устойчивости прогноза.
7. Внедрение и тестирование — интегрируйте модель в дашборд или торговый алгоритм и наблюдайте за результатами в реальном времени.
Нестандартные подходы к анализу on-chain данных

Помимо базовых метрик, нестандартный подход заключается в использовании поведенческих и сетевых индикаторов. Например, можно построить граф взаимодействий между адресами, выявляя кластеры крупных игроков. Такие данные можно использовать для создания индекса концентрации капитала. Другой метод — анализ задержек между событиями (например, всплеск активности перед ростом цены) с помощью временных рядов и марковских процессов. Также стоит учитывать данные из DeFi-протоколов: объем залоченных средств (TVL), процентное соотношение заемных и депозитных операций в протоколах может косвенно указывать на рыночную уверенность.
Еще один нестандартный подход — использование симуляции агентных моделей. В таком подходе каждый участник рынка моделируется как агент с определённой стратегией, и можно оценить, как изменение on-chain метрик влияет на поведение этих агентов. Это помогает уловить скрытые тренды, которые не видны в сырых данных.
Устранение неполадок и корректировка модели
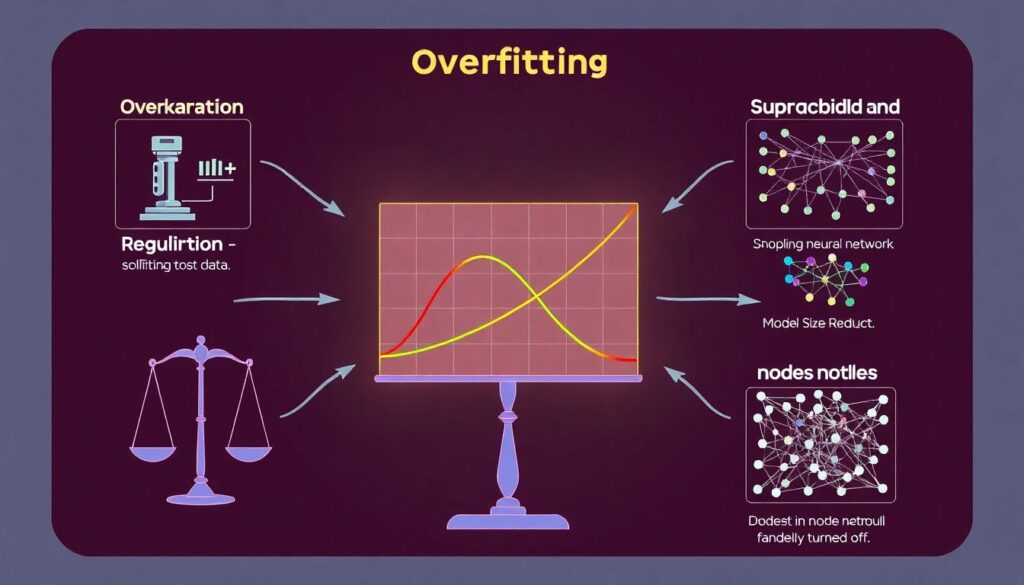
На практике модель может сталкиваться с различными проблемами. Первая — переобучение. Если модель слишком точно подстраивается под исторические данные, она будет плохо работать в будущем. Чтобы этого избежать, применяйте регуляризацию, уменьшайте размер модели или используйте dropout в нейросетях. Вторая распространённая ошибка — использование коррелирующих признаков. Это может ввести модель в заблуждение, особенно если изменить один параметр влияет на другой. Решение — применение анализа главных компонент (PCA) или удаление лишних признаков.
Если модель не показывает ожидаемой точности, стоит пересмотреть выбор метрик: возможно, стоит учитывать только активность смарт-контрактов определённых типов или фильтровать данные по времени суток. Также важно тестировать модель на “живых” данных: запустите её в режиме симуляции с задержкой и наблюдайте за результатами. Иногда помогает адаптивная фреймворк-модель, которая автоматически переобучается при изменении рыночного фона — особенно это актуально в волатильных условиях крипторынка.
Заключение
Модели ценообразования на основе on-chain данных требуют глубокого понимания как блокчейн-инфраструктуры, так и методов анализа данных. Успешные решения строятся на комбинации фундаментальных и поведенческих метрик, дополненных интеллектуальными методами машинного обучения. Для достижения лучших результатов важно не только грамотно собирать и обрабатывать данные, но и критически относиться к результатам, адаптируя модель к меняющимся условиям. Разработка таких моделей — это итеративный процесс, в котором нестандартное мышление и эксперименты часто приносят наибольшую ценность.