

Traceability in crypto research sounds dry until the moment you need to answer a brutal question:
“Why did we size this position like that, on that day, with that level of conviction?”
If you can’t reconstruct the chain of thought, data, and assumptions behind a decision, you’re flying blind. Traceability is about making every research conclusion reproducible, auditable, and explainable — to yourself in six months, to your team, or to an investment committee.
Let’s walk through how to make your crypto research workflows traceable without turning them into bureaucratic pain. I’ll mix in some unconventional tricks that actually work in real teams, not just in slide decks.
—
Why traceability in crypto research isn’t optional anymore
Crypto markets move fast, narratives mutate overnight, and new token models appear weekly. That chaos is exactly why traceability matters: it gives structure to an otherwise noisy environment.
In practice, “traceability” means you can follow a clean path from:
– Final thesis or decision
→ back to intermediate conclusions and scenario analysis
→ back to raw metrics and charts
→ back to original data sources and parameters you used.
For funds and serious desks, this traceability is a risk-control feature as much as a knowledge-management feature. When regulators, LPs, or internal risk committees ask how you used crypto research tools for funds to reach a view on a token, you want to pull up a coherent story backed by verifiable artifacts — not half-remembered Discord messages.
—
The minimum tool stack you actually need
You don’t need an enterprise monstrosity to get traceability. But you *do* need a deliberate stack that connects evidence, reasoning, and decisions.
At a high level, you want four layers of tools that talk to each other:
– Data & analytics layer – your windows into markets and blockchains.
– Computation & notebooks – where you transform data into insight.
– Knowledge & documentation – where the narrative and context live.
– Storage & governance – where you lock in versions, permissions, and retention.
Let’s unpack that in a more concrete way.
For the data layer, many teams combine centralized exchange data, DeFi protocols’ APIs, and at least one of the best crypto analytics platforms for traders. Tools like Glassnode, CryptoQuant, Kaiko, or Messari give you on-chain and market data with consistent schemas, and some are explicitly packaged as blockchain data providers for institutional investors with SLAs, dedicated support, and audit-friendly contracts.
On top of that, you’ll likely want *on-chain analytics software for crypto funds* that can trace wallet clusters, flows between entities, and contract interactions across chains. Think Nansen, Arkham, Flipside, or Dune dashboards — anything that can turn raw transactions into labeled behavior at the fund or whale level.
The computation layer is where you turn those feeds into models. This is often:
– Python/R notebooks (Jupyter, Quarto, VS Code)
– SQL environments connected to Dune/Flipside/BigQuery
– An internal analytics service that your quants maintain.
The trick for traceability: you treat code as *research evidence*, not just a scratchpad. That means versioning, comments, and stable environments.
For knowledge & documentation, avoid scattering notes across 10 tools. Use a single source of truth: Notion, Obsidian, Confluence, or even a well-structured Git repo with Markdown. Crypto portfolio tracking and research platforms (like Zerion, Rotki, or custom dashboards) can act as a “front-end” to strategy notes if you deliberately link each position to its research document.
Finally, the storage / governance layer is less sexy but critical: Git for code and notebooks, cloud drives with enforced folder structures, and role-based access. Traceability dies when “final_v3_really_final” appears in seven places.
—
A step-by-step traceable crypto research workflow
Here’s one concrete, reproducible workflow you can adapt. It’s designed so that *every step leaves breadcrumbs*.
1. Define the question in a structured template
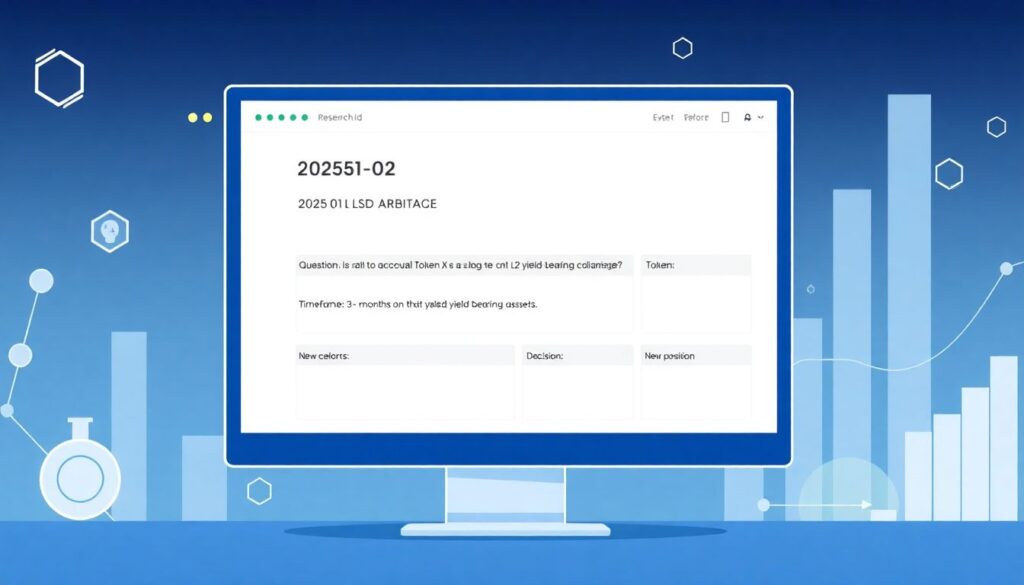
Before touching charts, open a research template. Keep it lightweight but consistent. For example:
– Research ID: `2025-01-L2-LSD-ARBITRAGE`
– Question: “Is it rational to accumulate Token X as a long-term bet on L2 yield-bearing collateral?”
– Timeframe: 3–12 months
– Decision type: *New position / Sizing change / Exit / Watchlist only*
Short step, but crucial: the Research ID will later tie your analytics, models, and final decision together.
2. Bind data sources to the question
Now you specify what data *should* answer that question. This prevents cherry-picking later.
Make a brief list, explicitly:
– Fundamentals: token emissions, FDV vs revenue, treasury health
– On-chain: active addresses, unique payers, liquidity profiles, holder distribution
– Market: realized volatility, open interest, perp funding, market depth
– Qualitative: protocol roadmap, governance risk, team behavior, ecosystem dependencies
Then map each to a concrete provider or query. This is where you connect the dots to your tools:
> “On-chain activity: Nansen entity flows + Dune dashboard `l2_token_x_activity_v5` (author: @alice, query hash: …)”
If you’re running a fund, this is where crypto research tools for funds and more retail-facing dashboards can coexist: you might use institutional-grade data in the core model and then double-check narrative resonance by scanning trader-heavy tools like CoinGlass, TradingView scripts, or retail sentiment scrapers.
3. Encode your analysis as code or parameterized queries
The biggest traceability win: avoid “clicked around for an hour, got a vibe from the charts.”
Whenever possible:
– Use reusable, parameterized SQL queries or notebook functions.
– Give them names that mirror the Research ID or at least the theme.
– Save the environment (libraries, versions, key configuration) along with the code.
You’re not trying to over-engineer every quick look. But if the analysis is serious enough to influence capital allocation, it’s serious enough to deserve a repeatable script or query.
A useful heuristic: if a chart or metric gets screenshot into a deck, the code or query that produced it must live in version control with a clear path back to the data source.
4. Write the narrative *last*, but link to every artifact
Once the analysis is in place, you convert math and charts into a thesis. Here’s the twist: don’t summarize everything in prose. Instead, keep the narrative short and heavily hyperlinked.
For example:
> “We observe a 3-month decline in new unique depositors (Query link) while TVL remains stable (Notebook cell link). This suggests concentration among existing whales rather than organic user growth. Combined with rising protocol incentives as a share of revenue (Model link), this weakens the long-term sustainability thesis.”
Each bold claim should have a link to:
– Specific chart or query
– Model cell or function
– Raw data snapshot, if it’s likely to change later.
You’re not writing a Medium post; you’re encoding an auditable line of reasoning.
5. Attach the research to the portfolio and decision record
Traceability collapses when research is siloed away from portfolio state. Connect the dots:
– In your internal dashboard or portfolio system, each position links to:
– Primary research doc (with the Research ID).
– Key risk metrics or alert thresholds derived from that research.
– Version tag of the main model/notebook.
Many crypto portfolio tracking and research platforms allow custom fields or notes. Use those to store the Research ID, date of last full review, and a one-liner about the thesis. This is low-effort, high-return: when markets nuke at 3 a.m., you can instantly see *why* you hold something and whether the thesis is still alive.
6. Make review and post-mortems first-class citizens
Traceability isn’t only about *past decisions*; it’s also about learning loops.
For every major position or theme:
– Schedule a recurring review (e.g., quarterly).
– Maintain a “What changed vs baseline?” section.
– If you exit or materially resize, write a 5–10 line post-mortem referencing original assumptions.
Over time, these post-mortems become a living dataset you can mine: “Which signals actually predicted drawdowns?” or “Which metrics consistently misled us?” That’s where on-chain analytics software for crypto funds starts to pay off at the process level — you can see which features matter for *your* style of trading or investing, not just what’s popular on Crypto Twitter.
—
Non-obvious tactics to improve traceability without drowning in paperwork
Here are some less standard, but very effective, moves.
Use “decision memos” as audio, not just text
Not everyone loves writing. Allow analysts to record short audio or video memos summarizing complex theses, then auto-transcribe them into your research system.
Workflow:
– Analyst records a 3–7 minute memo: what they looked at, what surprised them, what they’re uncertain about.
– Transcription is stored next to the doc, with links added later.
You capture nuance and tone (how confident were they *really*?), while still retaining searchable text and URLs. This can be especially powerful for fast-moving trades where formal docs lag execution.
Instrument your research steps like an application
If you’re a data-heavy shop, treat your research flow like code execution:
– Instrument “events”: query run, notebook committed, decision logged.
– Tag them with Research IDs and user IDs.
– Push these events into an internal analytics dashboard.
Now you can answer meta-questions:
– Which teams rely most on a specific blockchain data provider for institutional investors, and how often do they refresh data?
– How long does it usually take from “idea created” to “position opened”?
– Which analyses tend to get re-used across strategies?
This is process traceability, not just content traceability — and it reveals bottlenecks and single points of failure.
Build “opinionated templates” for different strategy types
Instead of one generic research template, create variants:
– Long-term fundamental thesis
– Event-driven / catalyst trades
– Quant/systematic signal research
– Governance or activist plays
Each template pre-asks the questions that matter, nudging analysts to capture traceable info specific to that strategy. For example, a short-term trader template might prioritize liquidity, spread, and funding, and tie directly into the best crypto analytics platforms for traders, while a long-term DeFi template foregrounds protocol profitability, tokenholder incentives, and adversarial scenarios.
Templates are boring only when they’re generic; when they’re strategy-specific, they massively increase signal density in your research archive.
—
Troubleshooting: where traceability breaks (and how to fix it)
Even with good intentions, crypto research workflows drift into chaos. Here’s where traceability usually fails — plus concrete fixes.
Problem 1: Everyone uses their own “secret tool zoo”
Analysts love their favorite dashboards and scrapers. That’s fine until nobody knows which numbers came from where.
Symptoms:
– Conflicting metrics for the same token from two people.
– “I think I saw this chart somewhere, but I can’t reproduce it.”
Fixes:
– Define a “canonical tool set” for core metrics (TVL, volumes, prices, addresses).
– Mark these in your templates: “TVL source: X by default; deviations must be noted.”
– Still allow experimentation, but require that any non-standard source be explicitly named and linked.
You’re not banning creativity; you’re forcing people to label their ingredients.
Problem 2: Snapshots disappear or mutate
On-chain and market data can be revised, recomputed, or re-labeled. Six months later, re-running a query might give different numbers.
Fixes:
– For any query that heavily influences a decision, export a snapshot (CSV or Parquet) to cold storage with a date and hash.
– Store hashes of critical datasets in Git or in a low-friction registry.
– When possible, pin key JSON outputs to IPFS or an internal object store, and reference that URI in your doc.
This preserves the *exact* dataset behind your thesis, even if upstream providers change calculations.
Problem 3: Notebook sprawl with zero version discipline
Notebooks are notorious for being half code, half diary, and zero documentation.
Fixes:
– Enforce a simple convention: one notebook per Research ID or theme, stored in a clear repo path.
– Require a “Header cell” with:
– Research ID
– Owner
– Purpose
– Key data sources and date of last full run
– Use a CI job (or a simple scheduled script) to periodically rerun key notebooks and report failures. Broken notebooks signal that your traceability chain is decaying.
Even a light-touch policy here drastically improves reproducibility.
Problem 4: Research and positions are not truly linked

If your portfolio system and research system don’t talk, traceability dies at the point of execution.
Fixes:
– Add mandatory fields to trade tickets: Research ID, thesis tag(s), and doc link.
– On the research side, embed position IDs or trade IDs in the doc.
– Periodically run a reconciliation script to flag:
– Positions without research.
– Research with no corresponding positions (stale or abandoned work).
This makes “orphan positions” visible — the ones nobody can really explain anymore.
Problem 5: No culture of retroactive honesty
Traceability is pointless if people rewrite history to make past decisions look smarter.
Fixes:
– Lock “original thesis” sections; create separate “amended view” sections with timestamps.
– Make post-mortems psychologically safe: focus on process flaws, not individual blame.
– Track what *was known at the time*, not what’s obvious today.
Over time, this builds a culture where documenting uncertainty and alternate scenarios is valued, not punished.
—
Pulling it together
Traceability for crypto research workflows isn’t about extra paperwork; it’s about building a living map of how your ideas turn into trades and investments.
The core pattern looks like this:
1. Give every research effort an identity.
2. Pre-commit to data sources and tools.
3. Encode analysis as code and parameterized queries.
4. Link narrative claims back to concrete artifacts.
5. Attach research to portfolio decisions and keep it updated.
6. Continuously debug the process itself, not just the models.
In a market as noisy and fast as crypto, the institutions that win long term are usually not the ones with the flashiest dashboard, but the ones who can answer, calmly and precisely:
“This is why we did what we did, this is the data we had, this is what we got wrong, and this is how we’re updating our process.”
That’s what real traceability buys you.