

Why event‑driven alerts for on-chain anomalies matter in 2025
If you touch real money on-chain, you’re already in the business of incident response — whether you admit it or not.
In 2024 одна only in DeFi, public incident trackers estimate over $1.7B lost to exploits and scams. The depressing part: in a large chunk of cases, there *were* on-chain signals minutes (sometimes hours) before the damage was irreversible. But teams either had no alerts, or they were drowning in noisy dashboards.
Event‑driven alerts for on-chain anomalies flip that situation. Instead of periodically “checking the chain”, you let the chain itself tell you — in real time — when something weird is happening.
Let’s walk through the practical side of this: what to monitor, how to wire alerts, what’s realistically doable in 2025, and where the space is heading next.
—
What “event‑driven” actually means in on‑chain monitoring
In traditional infra, event‑driven usually means: “something in production changed → an event fired → an alert was sent”. On-chain, the “events” are:
– New blocks
– New transactions
– Contract events and state changes
– Protocol‑level signals (reorgs, gas spikes, mempool anomalies)
The trick is to go from raw events to actionable crypto transaction monitoring alerts, without waking up your on‑call for every harmless whale transfer.
Event‑driven in this context means:
1. You subscribe to specific on‑chain events or patterns.
2. Anomaly logic runs immediately when those events appear (not every 5–15 minutes).
3. If conditions match, an alert is pushed to the right channel (Slack, PagerDuty, Telegram, custom webhook).
The key differentiator vs “polling dashboards”: latency. A solid real‑time on-chain analytics platform can process mainnet Ethereum events with median end‑to‑end delay well under 3–5 seconds from block inclusion to alert.
—
Core building blocks of event‑driven on‑chain alerts
1. Data ingestion: how you see the chain
Long paragraph:
You can’t detect anything if you don’t see it first. Teams usually choose between:
– Running their own full / archive nodes
– Using node providers (QuickNode, Alchemy, Infura, etc.)
– Using specialized blockchain security monitoring software that ships pre‑processed data, decoded events and ABIs
Running your own infra gives you control and fewer dependencies, but also ops burden (disk, pruning, upgrades, chain reorg handling). For most teams under 10 engineers, a mix of node providers plus a dedicated security / analytics vendor is the realistic sweet spot.
Technical detail — minimal ingestion setup
– Subscribe to `newHeads` (or equivalent) via WebSocket
– For each new block:
– Pull full transaction list
– For each tx, fetch receipt + logs
– Decode logs for contracts you care about using ABIs
– Optional but important:
– Track pending txs from the mempool if you care about ultra‑low‑latency front‑running / MEV‑related anomalies
—
2. Feature extraction: turning txs into signals
Shorter:
Raw transactions are too low‑level. Before you detect anything, you need to derive features. Examples:
– Value transferred in native token and stablecoins
– Token balance deltas of key wallets
– Outliers in gas usage or calldata size
– Changes in protocol parameters (e.g., collateral factors, fee rates)
– Role changes in governance or access‑controlled contracts
This is where most teams underestimate complexity. A simple token transfer is easy. Now add proxy contracts, upgradeable patterns, meta‑transactions, permit flows, bridges — and your extraction logic must keep up with new standards.
Technical detail — basic feature set for DeFi protocols
For each relevant transaction:
– Inputs:
– `from`, `to`, `value`, `gasUsed`, `effectiveGasPrice`
– Token transfers (decoded `Transfer` events)
– Contract events (e.g., `Mint`, `Borrow`, `Repay`, `Liquidate`)
– Derived features:
– Total USD notional moved (using price oracles or off‑chain feeds)
– % change in pool liquidity or TVL
– # of unique counterparties in last N minutes
– Whether call touched privileged functions (e.g., `setOwner`, `updateOracle`)
—
3. Anomaly logic: from features to “this is weird”
Longer again:
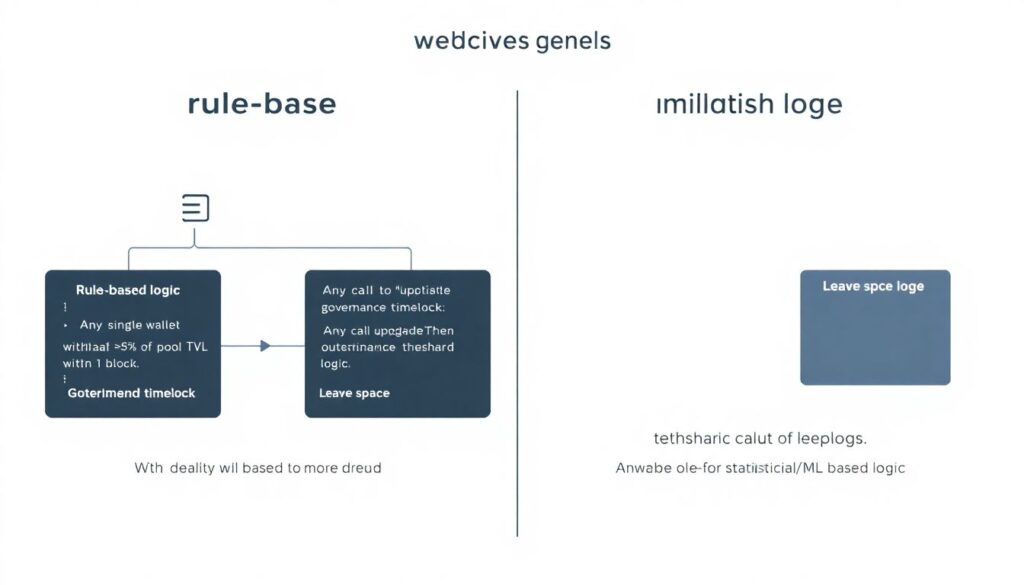
There are two main families of logic: rule‑based and statistical/ML‑based.
Rule‑based:
You explicitly codify patterns you care about. For example:
– “Any single wallet withdrawing >5% of pool TVL within 1 block”
– “Any call to `upgradeTo` function outside governance timelock”
– “Any token mint above historical 99.9th percentile in a 1‑hour window”
This is transparent and debuggable, but can miss novel attack vectors.
Statistical / ML:
Here, you use behavior baselines and detect deviations. For example:
– Wallet clusters whose interaction patterns suddenly change
– Protocol where “normal” withdrawals per hour are 50–100, but suddenly spike to 2,000 with small new wallets
– Unusual graph structure: new hubs appearing in your token transfer network
In production, teams rarely go “pure ML”. The pragmatic approach is rules + heuristics + a few statistical checks that are simple to interpret.
Technical detail — simple z‑score anomaly
For some metric `X` (e.g., number of liquidations per hour):
– Keep rolling window mean `μ` and standard deviation `σ` over last N hours
– Compute `z = (X_now – μ) / σ`
– Trigger a “soft” anomaly if `z > 3`, “hard” if `z > 6`
– Combine with rules, e.g. “z > 4 AND total notional > $10M AND # unique wallets < 5”
---
Designing useful alerts (so your team doesn’t mute them)
Alerts that nobody reads are a liability. Use event‑driven power carefully.
Step‑by‑step pattern for alert design
1. Define the incident class
What exactly are you trying to catch: governance takeover, oracle manipulation, rug pull, bridge exploit, treasury drain?
2. Map it to on‑chain precursors
For an oracle attack, this might be:
– Sudden deviation between on‑chain price and reference oracles
– Unusually large collateralized borrows immediately after a price move
3. Translate into events + conditions
Example:
– Event: `Borrow` on your lending contract
– Condition: `borrowed_amount_usd > 2 * historical_max_1h` AND `onchain_price / reference_price > 1.05`
4. Choose an escalation level
– Info: goes to monitoring channel, no wake‑up
– Warning: pings on‑call in working hours
– Critical: pages 24/7 through incident tool
5. Test in “shadow mode”
Run alerts for at least 1–2 weeks without paging, just logging, then review:
– False positives
– Blind spots (incidents missed)
6. Document the runbook
Every alert must have: “When you see this, do A → B → C”. No exception.
—
Real‑world examples from DeFi and bridges
Example 1: Lending protocol and collateral manipulation

Imagine a mid‑size lending protocol on Ethereum with ~$500M TVL. In 2024, similar protocols saw multiple near‑misses where price oracles were manipulated for just 2–3 blocks, allowing attackers to borrow under‑collateralized funds and flee.
What they configured:
– Event subscription:
– All `Borrow`, `Repay`, `Liquidate` events
– Oracle price updates
– Rules:
– If total borrows in a 5‑minute window > $25M AND average collateral ratio falls below historical 5th percentile → “Warning: abnormal borrow spike”.
– If oracle price deviates from two independent reference feeds (e.g., Chainlink + Uniswap TWAP) by > 7% for 2 consecutive blocks AND a large borrow occurs → “Critical: potential oracle exploit”.
Result in practice:
On one testnet‑mirrored incident, detection fired within 9 seconds after the malicious borrow transaction was included. Their human response (freezing a market via governance multisig) took ~3 minutes — but without the alert, they would have been blind for much longer.
—
Example 2: Bridge watching for abnormal withdrawals
Bridges remain one of the highest‑value honeypots: several well‑known hacks from 2021–2023 exceeded $500M each.
A production bridge in 2023–2024 used a web3 smart contract risk monitoring service plus their own rules:
– Monitored:
– Contract calls to `executeWithdraw` and `finalizeTransfer`
– Validator set changes on the bridge’s multisig
– Large NFT and token transfers through the bridge accounts
– Core alert:
– If a single validator unexpectedly increases its signing weight
– If > 2% of total bridged assets to a chain are withdrawn by new addresses within 10 minutes
Both conditions were wired as separate alerts that escalated directly to on‑call plus a pre‑defined “pause bridge” runbook (subject to governance policy).
In at least two situations, they saw weird but non‑malicious behavior (a partner exchange doing maintenance), tuned their thresholds, and avoided crying wolf the next time.
—
Connecting tools: you don’t need to build everything from scratch
In 2025, there’s no reason to reinvent the wheel. Modern on-chain anomaly detection tools already give you most of the plumbing:
– Chain ingestion
– Event decoding and ABI management
– Historical metrics and baselines
– Alert routing to Slack, email, PagerDuty, Opsgenie, etc.
Where you still need to invest engineering time is defining anomalies that matter for your specific protocol or business. Generic “high gas” alerts won’t save your treasury.
If you’re picking a provider, look for:
– Multiple chains and L2s supported (Ethereum, Arbitrum, OP Stack, Solana, Base, etc.)
– Low end‑to‑end latency (target < 5–10 seconds from block inclusion to alert)
- Ability to write custom logic (SQL, DSL, or code)
- Integrations with your incident tooling
A mature blockchain security monitoring software stack will also include:
- Historical dashboards for forensics
- Address labeling (exchanges, mixers, known attackers)
- API access for integrating your own data science or risk models
---
Where the data lives: on‑chain vs off‑chain signals
Not every anomaly can be fully observed on‑chain. Some critical context is off‑chain:
– KYC / KYB attributes of your users
– Centralized exchange deposit/withdraw patterns
– Internal risk scores
– Legal blacklists or sanctions lists
Modern pipelines often combine *on‑chain triggers* with *off‑chain enrichment*. Example workflow:
1. On‑chain: a large withdrawal from your protocol hits an alert threshold.
2. Off‑chain: you check whether this address belongs to a long‑time market maker, a top exchange, or a brand‑new wallet with zero history.
3. Decision: same on‑chain event, very different responses.
This is also where a real-time on-chain analytics platform becomes useful for cross‑referencing events across many protocols and chains, revealing patterns that are invisible from a single‑protocol view.
—
Performance and reliability: the boring parts that save you
Alert pipelines can themselves fail. A few practical tips:
– Redundancy
– Use at least two independent RPC sources or node providers.
– For critical alerts, send to at least two channels (e.g., Slack + PagerDuty).
– Backfill and reorg handling
– Chains reorg. Make sure your engine can:
– Mark alerts from orphaned blocks as “stale”
– Recompute anomalies on the canonical chain
– Rate limiting and aggregation
– During high‑volatility periods, anomalies might spike. Instead of 100 alerts in 2 minutes, aggregate:
– “95 similar alerts suppressed; see dashboard link”.
Technical detail — handling Ethereum reorgs
– Treat blocks as “soft final” for N confirmations (e.g., 12 blocks on Ethereum).
– For user‑facing alerts:
– Send immediately but mark as “pre‑finalization” if needed.
– If a block gets orphaned:
– Revoke or archive associated alerts.
– Recompute signals on the new canonical chain.
—
Forecast: where event‑driven on‑chain alerts are heading by 2030
We’re in 2025, and event‑driven alerts for on‑chain anomalies are moving from “nice‑to‑have” to regulatory and business necessity. Here’s what’s realistically coming next:
1. Regulator‑aligned monitoring by default
Compliance teams are starting to demand proactive blockchain monitoring, particularly after multiple large‑scale hacks with cross‑border impact. Expect:
– Standardized alert types (e.g., “suspicious mixer flow”, “sanctioned entity interaction”)
– Integration of crypto transaction monitoring alerts directly into centralized exchange compliance systems
2. Protocol‑native safety modules
Instead of alerts *only* waking humans, protocols will embed “circuit breakers”:
– If anomalies breach certain thresholds, parameters auto‑tighten: lower borrow caps, higher collateral ratios, slower withdrawals.
– Governance will review and ratify changes later, but damage is limited in real time.
3. More powerful cross‑chain correlation
Attackers already operate cross‑chain. Monitoring stacks will do the same:
– Correlate suspicious flow from L1 → bridge → L2 → DEX → mixer
– Use graph‑based models to spot “fund laundering trees” across dozens of chains
4. Commodity ML + specialized human expertise
ML models for on‑chain anomaly detection will increasingly be packaged as services and libraries, but high‑signal alerts will still depend on:
– Humans who deeply understand specific protocols and attack patterns
– Domain‑specific tuning and labeled incident datasets
5. Tighter coupling with insurance and risk pricing
On‑chain risk signals will be fed into:
– Protocol insurance pools
– Underwriting for institutional capital providing liquidity
– Dynamic pricing of premiums based on live risk level
In other words: by 2030, “we didn’t see it coming” will rarely be a credible excuse. The data is public, and the tooling is maturing quickly.
—
How to get started this quarter
If you’re building or operating anything non‑trivial on-chain in 2025, treat event‑driven alerts as part of your MVP security baseline, not a future upgrade. A simple phased plan:
1. Map your critical flows
– Deposits, withdrawals, upgrades, governance actions, price feeds.
2. Choose your on‑chain anomaly detection tools
– Either a commercial platform, an open‑source stack, or a hybrid with your own code.
3. Implement 5–10 high‑impact rules
– Focus on treasury, governance, and large user withdrawals first.
4. Hook into your incident workflows
– Connect to Slack, PagerDuty, or whatever you’re already using.
5. Iterate based on real alerts
– Review every week; tune thresholds; add missing logic.
The gap between “zero alerts” and a functioning event‑driven monitoring setup is smaller than it looks. The key is to start with a tight scope, wire it into the way your team already works, and expand as you learn.
Once your first genuine anomaly is caught in seconds instead of hours, there’s usually no going back.