
What we really mean by “validation”
When люди говорят про validation, они обычно мешают в одну кучу разные вещи. Давайте аккуратно разберёмся. Validation — это проверка входящих данных на корректность до того, как они попадут в бизнес‑логику или хранилище. То есть мы не говорим «правильный ли бизнес‑процесс», а всего лишь «данные похожи на то, что нам нужно?». Например, строка «2025-13-99» не проходит проверку даты, а телефон без кода страны не подходит под правила. В отличие от верификации, где вы подтверждаете факт (звонок клиенту, KYC), здесь мы проверяем форму и базовую осмысленность.
Почему validation стало так критично после 2022 года
С 2022 по конец 2024 года объём цифровых данных снова вырос примерно вдвое, по оценкам IDC и аналогичных отчётов, а вместе с ним вырос и объём «мусорных» записей. Многие компании заметили, что до 25–30% CRM‑профилей содержат ошибки в контактных данных: битые email, некорректные телефоны, странные адреса. Gartner в 2023 году оценивал годовые потери бизнеса от плохих данных примерно в 12–13 млн долларов на крупную организацию. На фоне роста автоматизации маркетинга и скоринга кредитов качество входных данных неожиданно стало не просто инженерной темой, а вопросом денег и юридических рисков.
Базовые термины: от синтаксиса до семантики
В разговоре про validation удобно разделять три уровня. Синтаксическая проверка: соответствует ли значение формату — длина строки, тип, регулярное выражение. Семантическая: значение имеет смысл в домене, например дата не в прошлом, сумма не отрицательная. И бизнес‑валидация: включены ли доменные правила, вроде «клиенту меньше 18, значит нельзя офорлять кредит». Эти три уровня часто реализованы в одном и том же data validation software, но полезно держать их в голове раздельно, чтобы понимать, какой слой у вас хромает в конкретной системе и где именно ломается логика.
Текстовые диаграммы: как данные проходят через проверки
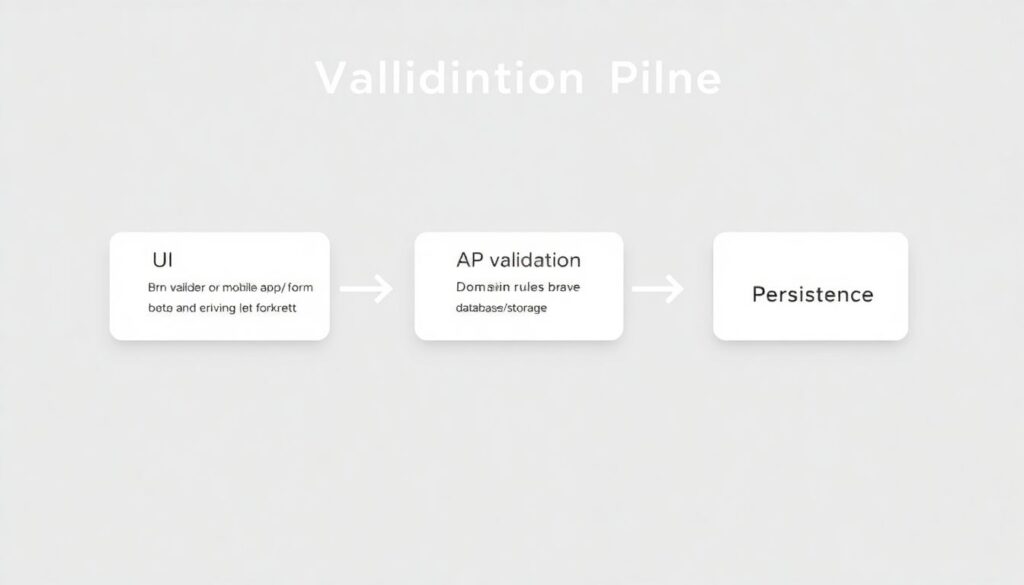
Представьте простой «конвейер» проверки данных. [Diagram: Client → UI validation → API validation → Domain rules → Persistence]. Сначала браузер или мобильное приложение запускает form validation plugin, отлавливая очевидные ошибки — пустые поля, неверный формат email. Затем запрос попадает в бэкенд, где включаются более строгие правила типов и длины. Далее подключаются доменные проверки: например, недопустимые комбинации полей или лимиты. И только в самом конце данные доходят до базы. Такой поэтапный подход позволяет ловить ошибки как можно раньше, экономя ресурсы сервера и время разработчиков.
Email, телефоны и адреса: валидация контактов без магии
Контактные данные — классический пример, где простых регулярных выражений мало. Хороший email validation service давно уже не ограничивается проверкой «есть ли собачка и точка». Он проверяет DNS‑записи, делает мягкий ping почтового сервера, пытается оценить временные домены. Похожие истории с телефонами: phone number validation tool сверяется со справочниками кодов стран, форматирует номер в E.164 и иногда проверяет, привязан ли он к реальной сети. Address validation api использует базы почтовых служб, геокодирование и справочники улиц, чтобы из «lenina 5 kv 7» сделать структурированный, пригодный для доставки адрес.
Клиентская и серверная validation: кто за что отвечает
В вебе с 2022 по 2024 годы несложно заметить тренд: фронтенд всё чаще берёт на себя «дружелюбные» проверки, а сервер ужесточает правила и не верит ничему извне. Клиентская validation в форме — это мгновенные подсказки и предотвращение глупых ошибок, вроде пустого обязательного поля или неправильного формата. Но полагаться только на неё опасно: скрипты легко обойти, а автоматизированные боты не уважают интерфейс. Поэтому серверная validation считается источником истины: она повторяет критичные проверки, добавляет доменные ограничения и защищает хранилище от вредных или просто хаотичных данных.
Диаграмма решений: где именно встраивать проверки
Если попытаться описать архитектуру проверки текстовой схемой, получится что‑то вроде: [Diagram: Input Source (form / API / batch file) → Validation Layer (schema checks, constraints, external services) → Processing Layer (business logic) → Storage]. Для потоковых систем часто добавляют ещё один блок: [Monitoring & Data Quality Metrics], который снимает статистику ошибок и своевременно сигналит, что что‑то пошло не так. Например, если вчера 2% заявок отклонялись из‑за некорректных паспортных данных, а сегодня уже 15%, это повод проверить как UX, так и возможные атаки ботов или баги в интеграции с внешней системой.
Сравнение подходов: ручная проверка против автоматизации
До примерно 2022 года многие компании в небольших сегментах рынка вообще обходились ручной проверкой данных: операторы обзванивали клиентов, перепроверяли email, уточняли адрес. Но с ростом объёмов это стало невозможным. Автоматизированные решения — будь то form validation plugin в CMS, отдельный микросервис или облачный пакет — позволяют проверять тысячи записей в минуту, не уставая и без человеческого фактора. Ручная проверка остаётся только там, где важны нюансы контекста, а автоматике сложно: сложные юридические кейсы, VIP‑клиенты, нестандартные договоры, где каждая деталь критична.
Статистика ошибок: что показывают последние три года

Если смотреть на отраслевые отчёты за 2022–2024 годы, картина довольно устойчивая. В среднем около 18–22% вводимых вручную данных содержат хотя бы одну ошибку: опечатка в имени, лишний символ в телефоне, неверный индекс. В e‑commerce компании, внедрившие автоматическую валидацию адресов и контактов, часто отчитываются о снижении возвратов посылок на 10–15% и росте доставляемости писем на 4–6%. Банки, усилившие валидацию форм и скоринговых анкет, отмечают сокращение ручной дообработки заявок до 30–40% за три года, что заметно разгружает back‑office и ускоряет кредитные решения.
Выбор инструментов: отдельные сервисы или встроенные решения
На уровне приложения разработчики спорят: использовать специализированные сервисы или полагаться на встроенный функционал фреймворков. data validation software в виде отдельного сервиса даёт гибкость: централизованные правила, версионирование схем, кросс‑языковую поддержку. С другой стороны, встроенные средства более естественно интегрируются в код. Компромисс — вынести общие схемы и правила в отдельный пакет или сервис, а в конкретных микросервисах лишь вызывать их. При этом для email и телефонов ресурсы вроде email validation service или phone number validation tool логично брать внешними SaaS, не изобретая велосипед.
Validation в мире data pipelines и аналитики
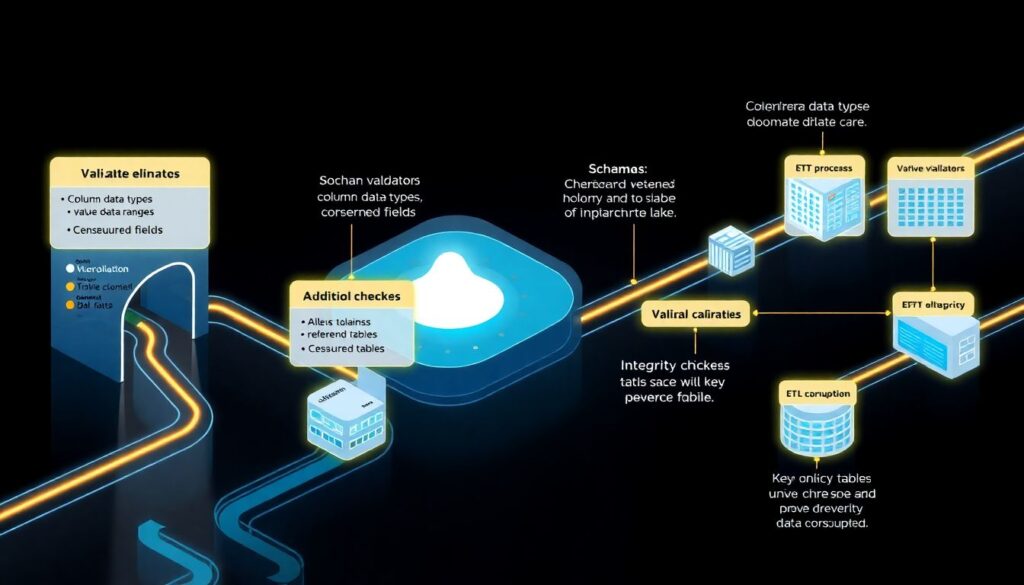
В аналитических конвейерах в последних трёх годах validation стала стандартной частью архитектуры. На входе в data lake проверяются схемы: типы столбцов, диапазоны значений, обязательные поля. Дальше в ETL‑процессах появляются проверки целостности: соответствие справочникам, уникальность ключей, непротиворечивость временных рядов. Появился термин «data contracts», когда команда‑поставщик данных обязуется поддерживать конкретную схему, а потребители автоматически валидируют её при каждом обновлении. Ошибки больше не прокрадываются тихо: при расхождении контрактов пайплайн падает, а ответственные команды получают отчёт с конкретными полями, нарушившими ожидания.
Куда движется validation к 2025 году
На 2025 год общая тенденция ясна: всё больше автоматизации и интеллекта поверх простых правил. Появляются модели, которые не только проверяют форматы, но и пытаются понять, «похожи ли данные на реальные» с учётом истории, географии и контекста пользователя. Одновременно усиливаются регуляторные требования к качеству данных, особенно в финансах и медицине: журналирование проверок, объяснимость правил, хранение причин отказа. Validation перестаёт быть скучной «проверкой формы» и превращается в стратегическую часть архитектуры, от которой напрямую зависят репутация бренда, юридическая устойчивость и, конечно, деньги.