
Понимание структуры и требований к крипто-данным
Определения ключевых терминов
Перед созданием расширенных наборов данных (англ. extended datasets) для крипто-исследований важно чётко определить основные понятия. Под крипто-данными подразумеваются структурированные сведения, извлечённые из блокчейнов, децентрализованных приложений (DApps), бирж, DeFi-протоколов и других источников, связанных с криптовалютной экосистемой. Расширенным считается набор данных, включающий несколько уровней агрегации: транзакционные данные, метаданные блоков, смарт-контрактные состояния и внешние метрики (например, рыночные цены, индикаторы ликвидности).
Также важно разграничивать термины «on-chain» (данные, находящиеся в блокчейне) и «off-chain» (внешние данные, такие как API бирж или макроэкономические параметры), поскольку объединение этих источников требует различных подходов к нормализации и синхронизации.
Структура типового расширенного набора данных
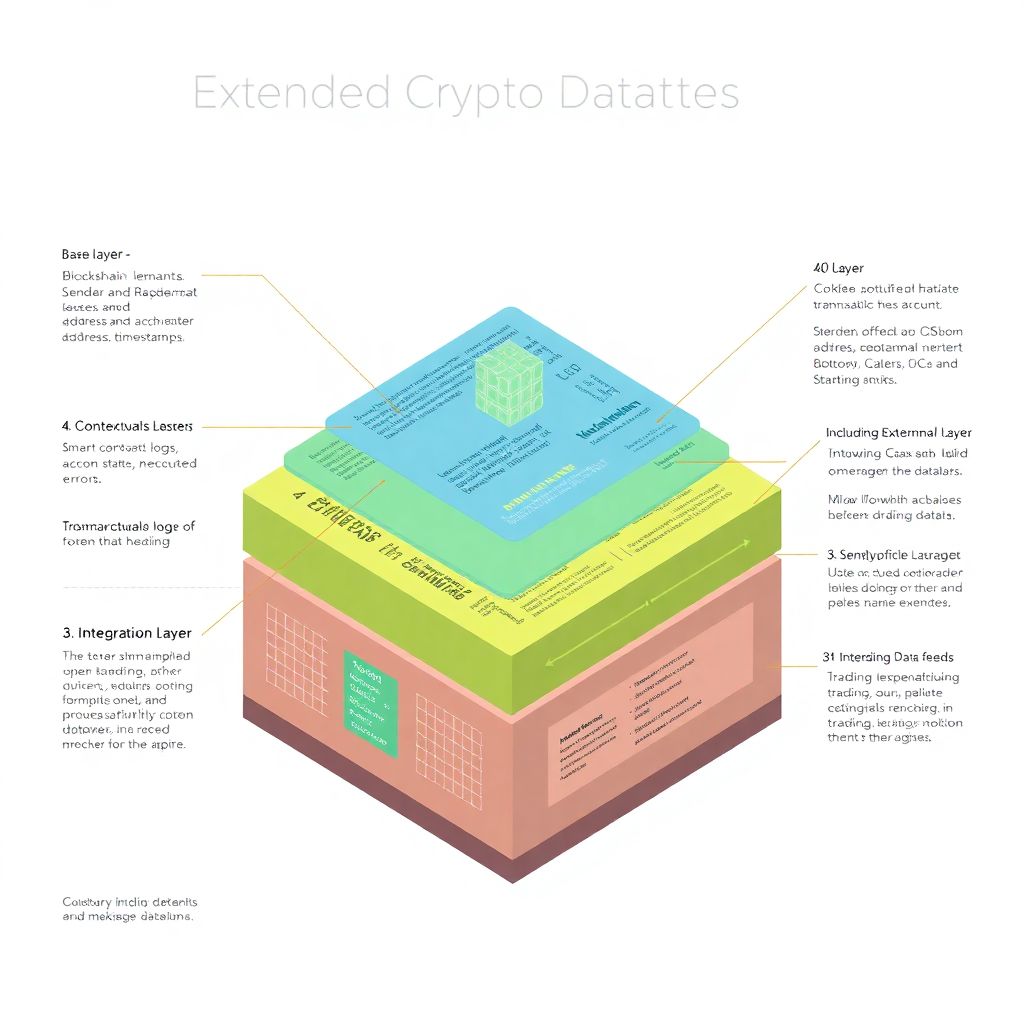
Расширенный крипто-набор данных состоит из нескольких взаимосвязанных слоёв. Описание структуры можно представить в виде диаграммы:
1. Слой 1 (Базовый): хеши транзакций, адреса отправителей и получателей, суммы, комиссии, временные метки.
2. Слой 2 (Контекстуальный): состояния аккаунтов, события смарт-контрактов (logs), вызовы функций и ошибки исполнения.
3. Слой 3 (Интеграционный): внешние цены токенов, объемы торгов, данные из Chainlink, Uniswap, CEX-API.
4. Слой 4 (Аналитический): агрегированные метрики — количество уникальных активных адресов, средние комиссии, коэффициенты волатильности.
Каждый слой может формироваться в виде отдельной сущности с привязкой к ключевым идентификаторам (например, идентификатор блока, хеш транзакции) для последующего соединения через реляционные или графовые структуры.
Методы извлечения и нормализации крипто-данных
Инструменты интеллектуального извлечения

Существует несколько подходов к сбору данных из блокчейнов:
1. RPC-интерфейсы и JSON-RPC-запросы. Используются для получения блоков, транзакций и состояний напрямую с узлов.
2. Архивные узлы. Необходимы при извлечении исторических состояний контрактов, недоступных через обычный RPC.
3. Парсеры событий (log parsers). Позволяют извлекать логи событий из смарт-контрактов — ключевой источник для анализа DeFi-протоколов.
4. Open-source индексационные фреймворки (например, The Graph, SubQuery). Автоматизируют создание индексов и ускоряют доступ к структурированным данным.
В ходе нормализации необходимо привести данные к унифицированному формату: стандартизировать временные метки (ISO 8601), наименования токенов (по стандарту ERC-20 или CAIP-19), использовать идентификаторы цепочек (Chain ID) и нормализовать числовые значения с учётом десятичных знаков токенов.
Обработка и фильтрация
Качественная фильтрация на этапе извлечения существенно снижает объём последующей очистки. Рекомендуется:
1. Исключать «dust»-транзакции (незначительные переводы менее $0.01).
2. Удалять транзакции с ошибками исполнения (Reverted).
3. Отклонять контракты без верифицированного исходного кода.
4. Фильтровать дубликаты событий, возникающие при реорганизации цепи (chain reorg).
Кроме того, важно внедрить механизмы валидации данных: проверка хешей, корректности форматов адресов, контроль полноты записей на уровне блоков.
Сравнение с альтернативными источниками
Сырые данные блокчейна против агрегаторов
Существует два принципиально различных подхода к получению крипто-данных: самостоятельное извлечение с использованием узлов и обращение к агрегаторам, таким как Dune, CryptoCompare, Nansen и Glassnode.
– Преимущества агрегаторов: Высокая скорость доступа, готовые метрики, визуализации, API-интерфейсы.
– Недостатки: Ограниченная гибкость, невозможность верификации источников, отсутствие редких или низкоуровневых данных.
Сырые данные, полученные с собственного узла, обеспечивают полный контроль, возможность анализа нестандартных сценариев (например, атаки MEV, фронт-раннинг), но требуют значительных вычислительных и хранилищных ресурсов.
Пример: анализ DEX-переводов
При анализе активности на децентрализованных биржах (DEX) можно использовать расширенные наборы данных, включающие:
– Сырые события Transfer и Swap из Uniswap V2/V3.
– Агрегированные пары токенов с ценами из Chainlink.
– Метаданные вызовов функций, включая отправителя, путь обмена, слиппейдж.
Такой набор позволяет построить точную модель изменения ликвидности, выявлять аномалии в торговом поведении и оценивать риски манипуляций в пуле.
Рекомендации по построению и хранению
Архитектура хранения и индексации
Хранилище расширенного крипто-набора должно быть масштабируемым, оптимизированным для аналитических запросов. Наиболее эффективны:
1. Data Lake на базе S3 + Apache Parquet. Подходит для хранения больших объемов с возможностью партиционирования.
2. Column-store БД (ClickHouse, BigQuery). Идеальны для агрегаций и временных рядов.
3. Графовые БД (Neo4j, Dgraph). Удобны для анализа взаимодействий между адресами и контрактами.
При построении индексов рекомендуется использовать первичные ключи: хеш транзакции, адрес контракта, временные интервалы. Также важно реализовать ETL-пайплайн с автоматическим обновлением, логированием ошибок и откатом при сбоях.
Экспертные рекомендации
1. Используйте архивные узлы только при необходимости: они ресурсоёмки и медленны, но незаменимы для исторического анализа.
2. Всегда валидируйте данные с несколькими источниками: особенно в случае off-chain API.
3. Внедрите систему версионирования данных: изменения в схемах смарт-контрактов требуют отслеживания версий.
4. Документируйте структуру и трансформации: метаданные повышают воспроизводимость исследований.
5. Стандартизируйте форматы токенов и адресов: используйте CAIP, EIP-55 и другие актуальные стандарты.
Заключение
Создание расширенных наборов данных для крипто-исследований требует глубокой технической экспертизы, понимания архитектуры блокчейнов и практического опыта работы с большими массивами данных. Такой подход обеспечивает не только точность аналитических моделей, но и открывает возможности для построения новых метрик, оценки поведения участников и мониторинга угроз в реальном времени. Устойчивость, масштабируемость и воспроизводимость — основные критерии качества крипто-данных в исследовательском контексте.